Release 9.2
Part Number A96517-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle Text Application Developer's Guide Release 9.2 Part Number A96517-01 |
|
This chapter introduces the main features of Oracle Text. It helps you to get started with indexing, querying, and document presentation.
The following topics are covered:
Oracle Text is a tool that enables you to build text query applications and document classification applications. Oracle Text provides indexing, word and theme searching, and viewing capabilities for text.
You can build two types of applications with Oracle Text, discussed in the following sections:
The purpose of a text query application is to enable users to find text that contains one or more search terms. The text is usually a collection of documents. A good application can index and search common document formats such as plain text, HTML, XML, or Microsoft Word. For example, an application with a browser interface might enable users to query a company Web site consisting of HTML files, returning those files that match a query.
To build a text query application, you create either a CONTEXT or CTXCAT index and query the index with CONTAINS or CATSEARCH operators respectively.
| See Also:
"Indexing Your Documents" in this chapter for more information about these indexes. |
A document classification application is one that classifies an incoming stream of documents based on its content. They are also known as document routing or filtering applications. For example, an online news agency might need to classify its incoming stream of articles as they arrive into categories such as politics, crime, and sports.
Oracle Text enables you to build these applications with the CTXRULE index. This index indexes the rules (queries) that define each class. When documents arrive, the MATCHES operator can be used to match each document with the rules that select it.
You can use the CTX_CLS.TRAIN procedure to generate rules on a document set. You can then create a CTXRULE index using the output from this procedure.
| See Also:
Oracle Text Reference for more information on CTX_CLS.TRAIN. |
For text query applications, Oracle Text supports most document formats for indexing and querying, including plain text, HTML and formatted documents such as Microsoft Word.
For document classification application, Oracle Text supports classifying plain text, HTML, and XML documents.
With Oracle Text, you can search on document themes if your language is English and French. To do so, you use the ABOUT operator in a CONTAINS query. For example, you can search for all documents that are about the concept politics. Documents returned might be about elections, governments, or foreign policy. The documents need not contain the word politics to score hits.
Theme information is derived from the supplied knowledge base, which is a hierarchical listing of categories and concepts. As the supplied knowledge base is a general view of the world, you can add to it new industry-specific concepts. With an augmented knowledge base, the system can process document themes more intelligently and so improve the accuracy of your theme searching.
With the supplied PL/SQL packages, you can also obtain document themes programatically.
| See Also:
Oracle Text Reference to learn more about the |
You can enable theme capabilities such as ABOUT queries in other languages besides English and French by loading a language-specific knowledge base.
To query, you use the SQL SELECT statement. Depending on your index, you can query text with either the CONTAINS operator, which is used with the CONTEXT index, or the CATSEARCH operator, which is used with the CTXCAT index.
You use these in the WHERE clause of the SELECT statement. For example, to search for all documents that contain the word oracle, you use CONTAINS as follows:
SELECT SCORE(1) title FROM news WHERE CONTAINS(text, 'oracle', 1) > 0;
To classify single documents, use the MATCHES operator with a CTXRULE index.
For text querying with the CONTAINS operator, Oracle Text provides a rich query language with operators that enable you to issue variety of queries including simple word queries, ABOUT operator queries, logical queries, and wildcard and thesaural expansion queries.
The CATSEARCH operator also supports some of the operations available with CONTAINS.
You can use the supplied Oracle Text PL/SQL packages for advanced features such as document presentation and thesaurus maintenance. Document presentation is how your application presents to the user documents in a query result set. You can maintain a thesaurus to expand queries and enhance your application.
To build an Oracle Text query application, you must have the following:
The following sections describe these prerequisites and also describe the main features of a generic text query application.
The basic prerequisite for an Oracle Text query application is to have a populated text table. The text table is where you store information about your document collection and is required for indexing.
You can populate rows in your text table with one of the following elements:
Figure 1-1, "Different Ways of Storing Text" illustrates these different methods.
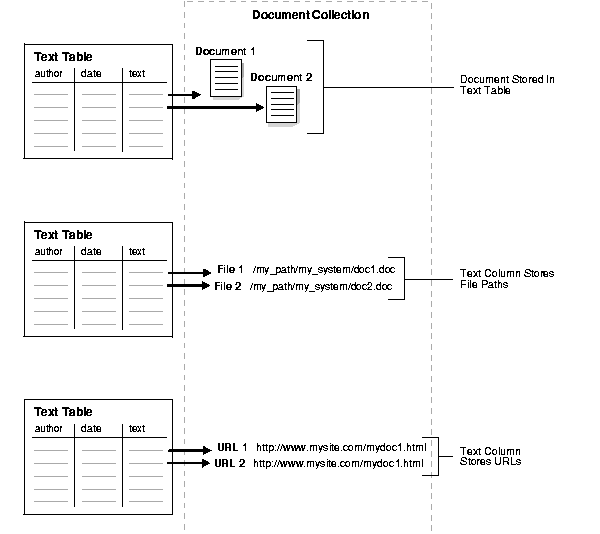
By default, the indexing operation expects your document text to be directly loaded in your text table, which is the first method above.
However, you can specify the other ways of identifying your documents such as with filenames or with URLs by using the corresponding data storage indexing preference.
You can store documents in your text table in different ways.
You can store documents in one column using the DIRECT_DATASTORE data storage type or over a number of columns using the MULTI_COLUMN_DATASTORE type. When your text is stored over a number of columns, Oracle concatenates the columns into a virtual document for indexing.
You can also create master-detail relationships for your documents, where one document can be stored across a number of rows. To create master-detail index, use the DETAIL_DATASTORE data storage type.
In your text table, you can also store short text fragments such as names, descriptions, and addresses over a number of columns and create a CTXCAT index. A CTXCAT index improves performance for mixed queries.
You can also store your text in a nested table using the NESTED_DATASTORE type.
Oracle Text supports the indexing of the XMLType datatype which you use to store XML documents.
In your text table, you can store path names to files stored in your file system. When you do so, use the FILE_DATASTORE preference type during indexing.
You can store URL names to index web-sites. When you do so, use the URL_DATASTORE preference type during indexing.
In your text table, you can create additional columns to store structured information that your query application might need, such as primary key, date, description, or author.
If your documents are of mixed formats or of mixed character sets, you can create the following additional columns:
TEXT or BINARY) to help filtering during indexing. You can also use to format column to ignore rows for indexing by setting the format column to IGNORE. This is useful for bypassing rows that contain data incompatible with text indexing such as images.When you create your index, you must specify the name of the format or character set column in the parameter clause of CREATE INDEX.
With Oracle Text, you can create a CONTEXT index with columns of type VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType.
Because the system can index most document formats including HTML, PDF, Microsoft Word, and plain text, you can load any supported type into the text column.
When you have mixed formats in your text column, you can optionally include a format column to help filtering during indexing. With the format column you can specify whether a document is binary (formatted) or text (non-formatted such as HTML).
| See Also:
Oracle Text Reference for more information about the supported document formats. |
The following sections describe different methods of loading information into a text column.
You can use the SQL INSERT statement to load text to a table.
The following example creates a table with two columns, id and text, by using the CREATE TABLE statement. This example makes the id column the primary key. The text column is VARCHAR2:
CREATE TABLE docs (id NUMBER PRIMARY KEY, text VARCHAR2(80));
To populate this table, use the INSERT statement as follows:
INSERT into docs values(1, 'this is the text of the first document'); INSERT into docs values(12, 'this is the text of the second document');
In addition to the INSERT statement, Oracle enables you to load text data (this includes documents, pointers to documents, and URLs) into a table from your file system by using other automated methods, including:
DBMS_LOB.LOADFROMFILE() PL/SQL procedure to load LOBs from BFILEsSee Also:
|
To query your document collection, you must first index the text column of your text table. Indexing breaks your text into tokens, which are usually words separated by spaces. Tokens can also be numbers, acronyms and other strings that are whitespace separated in the document.
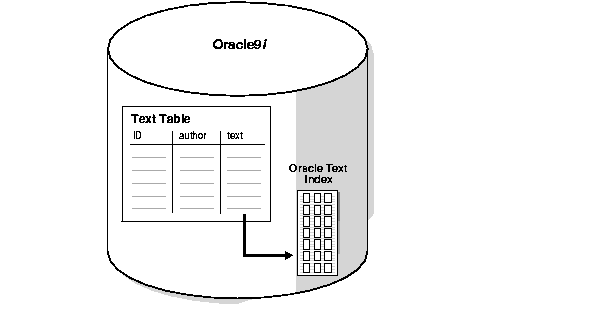
A CONTEXT index records each token and the documents that contain it. An inverted index as such allows for querying on words and phrases. Figure 1-2 shows a text table within Oracle9i and its associated Oracle Text index.
Oracle Text supports the creation of three types of indexes depending on your application and text source. You use the CREATE INDEX statement to create all types of Oracle Text indexes.
The following table describes these indexes and the type of applications you can build with them. The third column shows which query operator to use with the index.
Once your text data is loaded in a table, you can use the CREATE INDEX statement to create a CONTEXT index. When you create an index and specify no parameter clause, an index is created with default parameters.
For example, the following command creates a CONTEXT index with default parameters called myindex on the text column in the docs table:
CREATE INDEX myindex ON docs(text) INDEXTYPE IS CTXSYS.CONTEXT;
When you use CREATE INDEX to create a context index without explicitly specifying parameters, the system does the following for all languages by default:
CLOB, BLOB, BFILE, VARCHAR2, XMLType, or CHAR.|
Note: For document filtering to work correctly in your system, you must ensure that your environment is set up correctly to support the Inso filter. To learn more about configuring your environment to use the Inso filter, see Oracle Text Reference. |
You can always change the default indexing behavior by creating your own preferences and specifying these custom preferences in the parameter clause of CREATE INDEX.
By using the parameter clause with CREATE INDEX, you can customize your CONTEXT index. For example, in the parameter clause, you can specify where your text is stored, how you want it filtered for indexing, and whether sections should be created.
For example, to index a set of HTML files loaded in the text column htmlfile, you can issue the CREATE INDEX statement, specifying datastore, filter and section group parameters as follows:
CREATE INDEX myindex ON doc(htmlfile) INDEXTYPE IS ctxsys.context PARAMETERS ('datastore ctxsys.default_datastore filter ctxsys.null_filter section group ctxsys.html_section_group');
See Also:
|
A CTXCAT index is an index optimized for mixed queries. You can create this type of index when you store small documents or text fragments with associated structured information. To query this index, you use the CATSEARCH operator and specify a structured clause, if any. Query performance with a CTXCAT index is usually better for structured queries than with a CONTEXT index. To achieve better performance, your CTXCAT index must be configured correctly.
| See Also:
"Creating a CTXCAT Index" in Chapter 2, "Indexing" for a complete example |
You create a CTXRULE index to build a document classification application in which an incoming stream of documents is routed according content. You define the classification rules as queries which you index. You use the MATCHES operator to classify single documents.
| See Also:
"Creating a CTXRULE Index" in Chapter 2, "Indexing" for a complete example |
Index maintenance is necessary after your application inserts, updates, or deletes documents in your base table. Index maintenance involves synchronizing and optimizing your index.
If your base table is static, that is, your application does no updating, inserting or deleting of documents after your initial index, you do not need to synchronize your index.
However, if your application performs DML operations (inserts, updates, or deletes) on your base table, you must synchronize your index. You can synchronize your index manually with the CTX_DDL.SYNC_INDEX PL/SQL procedure.
The following example synchronizes the index myindex with 2 megabytes of memory:
begin ctx_ddl.sync_index('myindex', '2M');end;
If you synchronize your index regularly, you might also consider optimizing your index to reduce fragmentation and to remove old data.
| See Also:
"Managing DML Operations for a CONTEXT Index" in Chapter 2, "Indexing" for more information about synchronizing and optimizing the index. |
A typical query application enables the user to enter a query. The application executes the query and returns a list of documents, called a hit list usually ranked by relevance, that satisfy the query. The application enables the user to view one or more documents in the returned hitlist.
For example, an application might index URLs (HTML files) on the World Wide Web and provide query capabilities across the set of indexed URLs. Hit lists returned by the query application are composed of URLs that the user can visit.
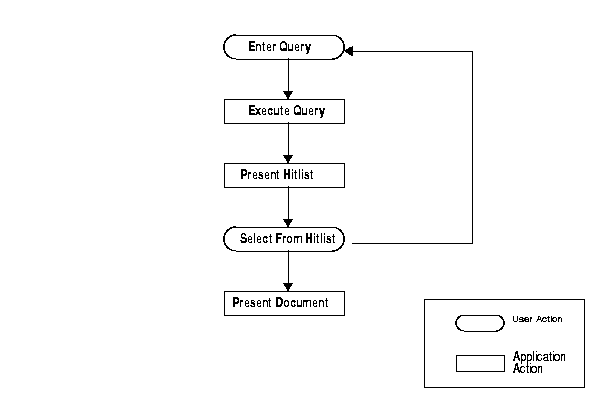
Figure 1-3 illustrates the flowchart of how a user interacts with a simple query application. The figure shows the steps required to enter the query and to view the results. Oval boxes indicate user-tasks and rectangular boxes indicate application tasks.
As shown, a query application can be modeled according to the following steps:
The rest of this chapter explains how you can accomplish these steps with Oracle Text.
| See Also:
Appendix A, "CONTEXT Query Application" for a description of a simple Web query application. |
With Oracle Text, you use the CONTAINS operator to query a CONTEXT index. This is the most common operator and index used to build query applications.
For more advanced applications, you use the CATSEARCH operator to query a CTXCAT index, and you use the MATCHES operator to query the CTXRULE index.
You can use the CONTAINS operator to retrieve documents that contain a word or phrase. Your document must be indexed before you can issue a CONTAINS query.
Use the CONTAINS operator in a SELECT statement. With CONTAINS, you can issue two types of queries:
You can also optimize queries for better response time to obtain a specified number of the highest ranking (top n) hits. The following sections give an overview of these query scenarios.
A word query is a query on the exact word or phrase you enter between the single quotes in the CONTAINS or CATSEARCH operator.
The following example finds all the documents in the text column that contain the word oracle. The score for each row is selected with the SCORE operator by using a label of 1:
SELECT SCORE(1) title FROM news WHERE CONTAINS(text, 'oracle', 1) > 0;
In your query expression, you can use text operators such as AND and OR to achieve different results. You can also add structured predicates to the WHERE clause.
| See Also:
Oracle Text Reference for more information about the different operators you can use in queries |
You can count the hits to a query by using the SQL COUNT(*) statement, or the CTX_QUERY.COUNT_HITS PL/SQL procedure.
You issue ABOUT queries with the ABOUT operator in the CONTAINS clause.
In all languages, ABOUT queries increases the number of relevant documents returned by a query.
In English and French, ABOUT queries can use the theme component of the index, which is created by default. As such, this operator returns documents based on the concepts of your query, not only the exact word or phrase you specify.
For example, the following query finds all the documents in the text column that are about the subject politics, not just the documents that contain the word politics:
SELECT SCORE(1) title FROM news WHERE CONTAINS(text, 'about(politics)', 1) > 0;
| See Also:
Oracle Text Reference to learn more about the |
You can optimize any CONTAINS query (word or ABOUT) for response time in order to retrieve the highest ranking hits in a result set in the shortest possible time. Optimizing for response time is useful in a Web-based search application.
Your application interface can give the user the option of querying on structured fields related to the text such as item description, author, or date as a means of further limiting the search criteria.
You can issue structured searches with the CONTAINS operator by using a structured clause in the SELECT statement. However, for optimal performance, consider creating a CTXCAT index, which gives better performance for structured queries with the CATSEARCH operator.
Your application can also present the structured information related to each document in the hit list.
| See Also:
"Creating a CTXCAT Index" in Chapter 2, "Indexing" for more information about creating a |
Oracle Text enables you to define a thesaurus for your query application.
Defining a custom thesaurus enables you to process queries more intelligently. Since users of your application might not know which words represent a topic, you can define synonyms or narrower terms for likely query terms. You can use the thesaurus operators to expand your query to include thesaurus terms.
Section searching enables you to narrow text queries down to sections within documents.
Section searching can be implemented when your documents have internal structure, such as HTML and XML documents. For example, you can define a section for the <H1> tag that enables you to query within this section using the WITHIN operator.
You can set the system to automatically create sections from XML documents.
You can also define attribute sections to search attribute text in XML documents.
In your query application, you can use other query features such as proximity searching. Table 1-1 lists some of these features.
After executing the query, query applications typically present a hit list of all documents that satisfy the query along with a relevance score. This list can be a list of document titles or URLs depending on your document set.
Your application presents a hitlist in one or more of the following ways:
Figure 1-4 is a screen shot of a query application presenting the hit list to the user.
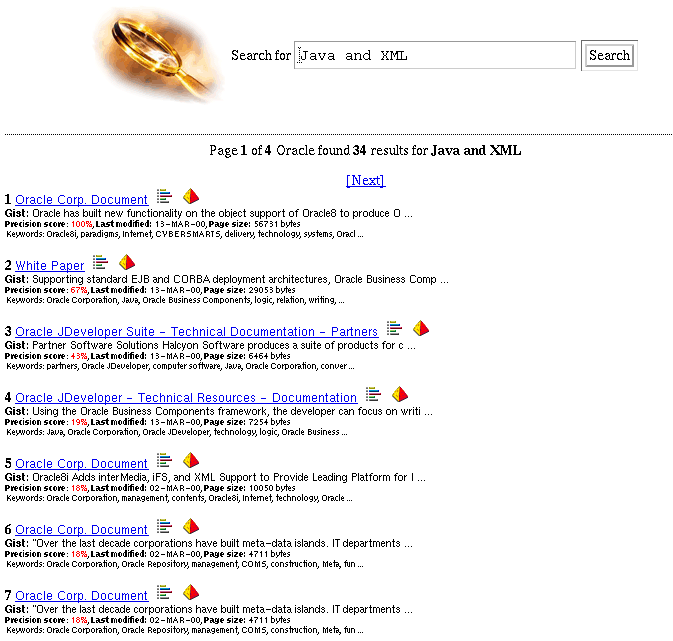
Text description of the illustration fig3.gif
Structured columns related to the text column can help to identify documents. When you present the hit list, you can show related columns such as document titles or author or any other combination of fields that identify the document.
You specify the name of the structured columns that you want to include in the hit list in the SELECT statement.
When you issue either a text query or a theme query, Oracle returns the hit list of documents that satisfy the query with a relevance score for each document returned. You can use these scores to order the hitlist to show the most relevant documents first.
The score for each document is between 1 and 100. The higher the score, the more relevant the document to the query.
Oracle calculates scores when you use the CONTAINS or CATSEARCH operators. You obtain scores using the SCORE operator.
You can present the number of hits the query returned alongside the hit list, using SELECT COUNT(*). For example:
SELECT COUNT(*) FROM docs WHERE CONTAINS(text, 'oracle', 1) > 0;
To count hits in PL/SQL, you can also use the CTX_QUERY.COUNT_HITS procedure.
Typically, a query application enables the user to view the documents returned by a query. The user selects a document from the hit list and then the application presents the document in some form.
With Oracle Text, you can display a document in different ways. For example, you can present documents with query terms highlighted. Highlighted query terms can be either the words of a word query or the themes of an ABOUT query in English.
You can also obtain gist (document summary) and theme information from documents with the CTX_DOC PL/SQL package.
Table 1-2 describes the different output you can obtain and which procedure to use to obtain each type.
Figure 1-5 is a screen shot of a query application presenting a document with the query terms heart and lungs highlighted.

Text description of the illustration highligh.gif
Figure 1-6 is a screen shot of a query application presenting a list of themes for a document.
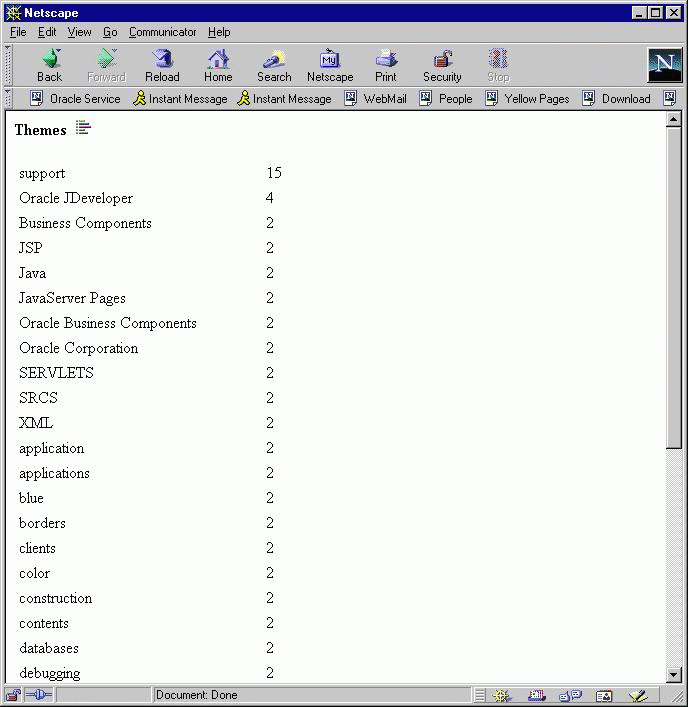
Text description of the illustration themes.gif
Figure 1-7 is a screen shot of a query application presenting a gist for a document.
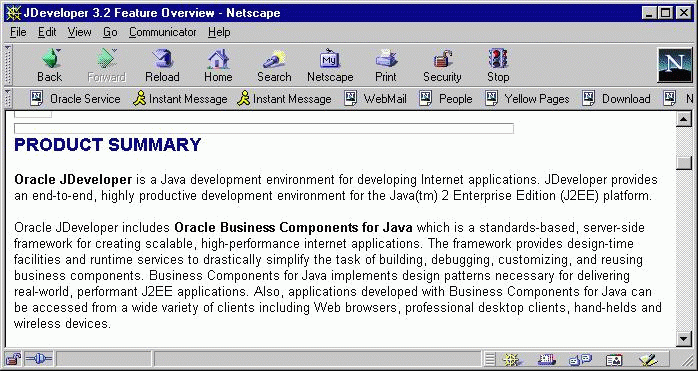
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

