Release 2 (9.2)
Part Number A96652-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Database Utilities Release 2 (9.2) Part Number A96652-01 |
|
This chapter describes the SQL*Loader control file. The following topics are included:
The SQL*Loader control file is a text file that contains data definition language (DDL) instructions. DDL is used to control the following aspects of a SQL*Loader session:
See Appendix A for syntax diagrams of the SQL*Loader DDL.
To create the SQL*Loader control file, use a text editor such as vi or xemacs.create.
In general, the control file has three main sections, in the following order:
Example 5-1 shows a sample control file.
1 -- This is a sample control file 2 LOAD DATA 3 INFILE 'sample.dat' 4 BADFILE 'sample.bad' 5 DISCARDFILE 'sample.dsc' 6 APPEND 7 INTO TABLE emp 8 WHEN (57) = '.' 9 TRAILING NULLCOLS 10 (hiredate SYSDATE, deptno POSITION(1:2) INTEGER EXTERNAL(2) NULLIF deptno=BLANKS, job POSITION(7:14) CHAR TERMINATED BY WHITESPACE NULLIF job=BLANKS "UPPER(:job)", mgr POSITION(28:31) INTEGER EXTERNAL TERMINATED BY WHITESPACE, NULLIF mgr=BLANKS, ename POSITION(34:41) CHAR TERMINATED BY WHITESPACE "UPPER(:ename)", empno POSITION(45) INTEGER EXTERNAL TERMINATED BY WHITESPACE, sal POSITION(51) CHAR TERMINATED BY WHITESPACE "TO_NUMBER(:sal,'$99,999.99')", comm INTEGER EXTERNAL ENCLOSED BY '(' AND '%' ":comm * 100" )
In this sample control file, the numbers that appear to the left would not appear in a real control file. They are keyed in this sample to the explanatory notes in the following list:
LOAD DATA statement tells SQL*Loader that this is the beginning of a new data load. See Appendix A for syntax information.INFILE clause specifies the name of a datafile containing data that you want to load. See Specifying Datafiles.BADFILE parameter specifies the name of a file into which rejected records are placed. See Specifying the Bad File.DISCARDFILE parameter specifies the name of a file into which discarded records are placed. See Specifying the Discard File.APPEND parameter is one of the options you can use when loading data into a table that is not empty. See Loading Data into Nonempty Tables.
To load data into a table that is empty, you would use the INSERT parameter. See Loading Data into Empty Tables.
INTO TABLE clause allows you to identify tables, fields, and datatypes. It defines the relationship between records in the datafile and tables in the database. See Specifying Table Names.WHEN clause specifies one or more field conditions. SQL*Loader decides whether or not to load the data based on these field conditions. See Loading Records Based on a Condition.TRAILING NULLCOLS clause tells SQL*Loader to treat any relatively positioned columns that are not present in the record as null columns. See Handling Short Records with Missing Data.Comments can appear anywhere in the command section of the file, but they should not appear within the data. Precede any comment with two hyphens, for example:
--This is a comment
All text to the right of the double hyphen is ignored, until the end of the line. An example of comments in a control file is shown in Case Study 3: Loading a Delimited, Free-Format File.
The OPTIONS clause is useful when you typically invoke a control file with the same set of options. The OPTIONS clause precedes the LOAD DATA statement.
The OPTIONS clause allows you to specify runtime parameters in the control file, rather than on the command line. The following parameters can be specified using the OPTIONS clause. These parameters are described in greater detail in Chapter 4.
BINDSIZE =nCOLUMNARRAYROWS = n DIRECT = {TRUE | FALSE} ERRORS = n LOAD = n MULTITHREADING = {TRUE | FALSE} PARALLEL = {TRUE | FALSE} READSIZE = n RESUMABLE = {TRUE | FALSE} RESUMABLE_NAME = 'text string' RESUMABLE_TIMEOUT =nROWS = n SILENT = {HEADERS | FEEDBACK | ERRORS | DISCARDS | PARTITIONS | ALL} SKIP = n SKIP_INDEX_MAINTENANCE = {TRUE | FALSE} SKIP_UNUSABLE_INDEXES = {TRUE | FALSE} STREAMSIZE = n
For example:
OPTIONS (BINDSIZE=100000, SILENT=(ERRORS, FEEDBACK) )
|
Note: Values specified on the command line override values specified in the |
In general, SQL*Loader follows the SQL standard for specifying object names (for example, table and column names). The information in this section discusses the following topics:
SQL and SQL*Loader reserved words must be specified within double quotation marks. The only SQL*Loader reserved word is CONSTANT.
You must use double quotation marks if the object name contains special characters other than those recognized by SQL ($, #, _), or if the name is case sensitive.
You must specify SQL strings within double quotation marks. The SQL string applies SQL operators to data fields.
The following sections discuss situations in which your course of action may depend on the operating system you are using.
If you encounter problems when trying to specify a complete path name, it may be due to an operating system-specific incompatibility caused by special characters in the specification. In many cases, specifying the path name within single quotation marks prevents errors.
If not, please see your Oracle operating system-specific documentation for possible solutions.
In DDL syntax, you can place a double quotation mark inside a string delimited by double quotation marks by preceding it with the escape character, "\" (if the escape character is allowed on your operating system). The same rule applies when single quotation marks are required in a string delimited by single quotation marks.
For example, homedir\data"norm\mydata contains a double quotation mark. Preceding the double quotation mark with a backslash indicates that the double quotation mark is to be taken literally:
INFILE 'homedir\data\"norm\mydata'
You can also put the escape character itself into a string by entering it twice:
For example:
"so'\"far" or 'so\'"far' is parsed as so'"far "'so\\far'" or '\'so\\far\'' is parsed as 'so\far' "so\\\\far" or 'so\\\\far' is parsed as so\\far
|
Note: A double quotation mark in the initial position cannot be preceded by an escape character. Therefore, you should avoid creating strings with an initial quotation mark. |
There are two kinds of character strings in a SQL*Loader control file that are not portable between operating systems: filename and file processing option strings. When you convert to a different operating system, you will probably need to modify these strings. All other strings in a SQL*Loader control file should be portable between operating systems.
If your operating system uses the backslash character to separate directories in a path name, and if the version of the Oracle database server running on your operating system implements the backslash escape character for filenames and other nonportable strings, then you must specify double backslashes in your path names and use single quotation marks.
See your Oracle operating system-specific documentation for information about which escape characters are required or allowed.
The version of the Oracle database server running on your operating system may not implement the escape character for nonportable strings. When the escape character is disallowed, a backslash is treated as a normal character, rather than as an escape character (although it is still usable in all other strings). Then path names such as the following can be specified normally:
INFILE 'topdir\mydir\myfile'
Double backslashes are not needed.
Because the backslash is not recognized as an escape character, strings within single quotation marks cannot be embedded inside another string delimited by single quotation marks. This rule also holds for double quotation marks. A string within double quotation marks cannot be embedded inside another string delimited by double quotation marks.
To specify a datafile that contains the data to be loaded, use the INFILE clause, followed by the filename and optional file processing options string. You can specify multiple files by using multiple INFILE clauses.
|
Note: You can also specify the datafile from the command line, using the |
If no filename is specified, the filename defaults to the control filename with an extension or file type of .dat.
If the control file itself contains the data to be loaded, specify an asterisk (*). This specification is described in Identifying Data in the Control File with BEGINDATA .
|
Note: The information in this section applies only to primary datafiles. It does not apply to LOBFILEs or SDFs. For information about LOBFILES, see Loading LOB Data from LOBFILEs. For information about SDFs, see Secondary Datafiles (SDFs). |
The syntax for the INFILE clause is as follows:

Text description of the illustration infile.gif
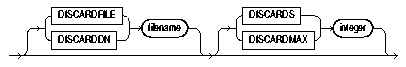
Text description of the illustration infile2.gif
Table 5-1 describes the parameters for the INFILE clause.
| Parameter | Description |
|---|---|
|
Specifies that a datafile specification follows. Note that |
|
|
Name of the file containing the data. Any spaces or punctuation marks in the filename must be enclosed in single quotation marks. See Specifying Filenames and Object Names. |
|
|
* |
If your data is in the control file itself, use an asterisk instead of the filename. If you have data in the control file as well as datafiles, you must specify the asterisk first in order for the data to be read. |
|
|
This is the file-processing options string. It specifies the datafile format. It also optimizes datafile reads. The syntax used for this string is specific to your operating system. See Specifying Datafile Format and Buffering. |
The following list shows different ways you can specify INFILE syntax:
INFILE *
foo with a default extension of .dat:
INFILE foo
datafile.dat with a full path specified:
INFILE 'c:/topdir/subdir/datafile.dat'
|
Note: Filenames that include spaces or punctuation marks must be enclosed in single quotation marks. For more details on filename specification, see Specifying Filenames and Object Names. |
To load data from multiple datafiles in one SQL*Loader run, use an INFILE statement for each datafile. Datafiles need not have the same file processing options, although the layout of the records must be identical. For example, two files could be specified with completely different file processing options strings, and a third could consist of data in the control file.
You can also specify a separate discard file and bad file for each datafile. In such a case, the separate bad files and discard files must be declared immediately after each datafile name. For example, the following excerpt from a control file specifies four datafiles with separate bad and discard files:
INFILE mydat1.dat BADFILE mydat1.bad DISCARDFILE mydat1.dis INFILE mydat2.dat INFILE mydat3.dat DISCARDFILE mydat3.dis INFILE mydat4.dat DISCARDMAX 10 0
mydat1.dat, both a bad file and discard file are explicitly specified. Therefore both files are created, as needed.mydat2.dat, neither a bad file nor a discard file is specified. Therefore, only the bad file is created, as needed. If created, the bad file has the default filename and extension mydat2.bad. The discard file is not created, even if rows are discarded.mydat3.dat, the default bad file is created, if needed. A discard file with the specified name (mydat3.dis) is created, as needed.mydat4.dat, the default bad file is created, if needed. Because the DISCARDMAX option is used, SQL*Loader assumes that a discard file is required and creates it with the default name mydat4.dsc.If the data is included in the control file itself, then the INFILE clause is followed by an asterisk rather than a filename. The actual data is placed in the control file after the load configuration specifications.
Specify the BEGINDATA parameter before the first data record. The syntax is:
BEGINDATA data
Keep the following points in mind when using the BEGINDATA parameter:
BEGINDATA parameter but include data in the control file, SQL*Loader tries to interpret your data as control information and issues an error message. If your data is in a separate file, do not use the BEGINDATA parameter.BEGINDATA parameter, or the line containing BEGINDATA will be interpreted as the first line of data.BEGINDATA, or they will also be interpreted as data.
See Also:
|
When configuring SQL*Loader, you can specify an operating system-dependent file processing options string (os_file_proc_clause) in the control file to specify file format and buffering.
For example, suppose that your operating system has the following option-string syntax:
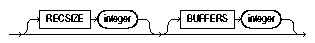
Text description of the illustration recsize.gif
In this syntax, RECSIZE is the size of a fixed-length record, and BUFFERS is the number of buffers to use for asynchronous I/O.
To declare a file named mydata.dat as a file that contains 80-byte records and instruct SQL*Loader to use 8 I/O buffers, you would use the following control file entry:
INFILE 'mydata.dat' "RECSIZE 80 BUFFERS 8"
For details on the syntax of the file processing options string, see your Oracle operating system-specific documentation.
|
Note: This example uses the recommended convention of single quotation marks for filenames and double quotation marks for everything else. |
When SQL*Loader executes, it can create a file called a bad file or reject file in which it places records that were rejected because of formatting errors or because they caused Oracle errors. If you have specified that a bad file is to be created, the following applies:
To specify the name of the bad file, use the BADFILE parameter (or BADDN for DB2 compatibility), followed by the bad file filename. If you do not specify a name for the bad file, the name defaults to the name of the datafile with an extension or file type of .bad. You can also specify the bad file from the command line with the BAD parameter described in Command-Line Parameters.
A filename specified on the command line is associated with the first INFILE or INDDN clause in the control file, overriding any bad file that may have been specified as part of that clause.
The bad file is created in the same record and file format as the datafile so that the data can be reloaded after making corrections. For datafiles in stream record format, the record terminator that is found in the datafile is also used in the bad file.
The syntax for the bad file is as follows:
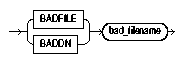
Text description of the illustration badfile.gif
The BADFILE or BADDN parameter specifies that a filename for the bad file follows. (Use BADDN when DB2 compatibility is required.)
The bad_filename parameter specifies a valid filename specification for your platform. Any spaces or punctuation marks in the filename must be enclosed in single quotation marks.
To specify a bad file with filename foo and default file extension or file type of .bad, enter:
BADFILE foo
To specify a bad file with filename bad0001 and file extension or file type of .rej, enter either of the following lines:
BADFILE bad0001.rej BADFILE '/REJECT_DIR/bad0001.rej'
Data from LOBFILEs and SDFs is not written to a bad file when there are rejected rows. If there is an error loading a LOB, the row is not rejected. Rather, the LOB column is left empty (not null with a length of zero (0) bytes). However, when the LOBFILE is being used to load an XML column and there is an error loading this LOB data, then the XML column is left as null.
A record can be rejected for the following reasons:
If the data can be evaluated according to the WHEN clause criteria (even with unbalanced delimiters), then it is either inserted or rejected.
Neither a conventional path nor a direct path load will write a row to any table if it is rejected because of reason number 2 in the previous list.
Additionally, a conventional path load will not write a row to any tables if reason number 1 or 3 in the previous list is violated for any one table. The row is rejected for that table and written to the reject file.
The log file indicates the Oracle error for each rejected record. Case Study 4: Loading Combined Physical Records demonstrates rejected records.
During SQL*Loader execution, it can create a discard file for records that do not meet any of the loading criteria. The records contained in this file are called discarded records. Discarded records do not satisfy any of the WHEN clauses specified in the control file. These records differ from rejected records. Discarded records do not necessarily have any bad data. No insert is attempted on a discarded record.
A discard file is created according to the following rules:
WHEN clauses specified in the control file. (If the discard file is created, it overwrites any existing file with the same name, so be sure that you do not overwrite any files you wish to retain.)To create a discard file from within a control file, specify any of the following: DISCARDFILE filename, DISCARDDN filename (DB2), DISCARDS, or DISCARDMAX.
To create a discard file from the command line, specify either DISCARD or DISCARDMAX.
You can specify the discard file directly by specifying its name, or indirectly by specifying the maximum number of discards.
The discard file is created in the same record and file format as the datafile. For datafiles in stream record format, the same record terminator that is found in the datafile is also used in the discard file.
To specify the name of the file, use the DISCARDFILE or DISCARDDN (for DB2-compatibility) parameter, followed by the filename.

Text description of the illustration discard.gif
The DISCARDFILE or DISCARDDN parameter specifies that a discard filename follows. (Use DISCARDDN when DB2 compatibility is required.)
The discard_filename parameter specifies a valid filename specification for your platform. Any spaces or punctuation marks in the filename must be enclosed in single quotation marks.
The default filename is the name of the datafile, and the default file extension or file type is .dsc. A discard filename specified on the command line overrides one specified in the control file. If a discard file with that name already exists, it is either overwritten or a new version is created, depending on your operating system.
See DISCARD (filename) for information on how to specify a discard file from the command line.
A filename specified on the command line overrides any discard file that you may have specified in the control file.
The following list shows different ways you can specify a name for the discard file from within the control file:
circular and default file extension or file type of .dsc:
DISCARDFILEcircular
notappl with the file extension or file type of .may:
DISCARDFILE notappl.may
forget.me:
DISCARDFILE '/discard_dir/forget.me'
If there is no INTO TABLE clause specified for a record, the record is discarded. This situation occurs when every INTO TABLE clause in the SQL*Loader control file has a WHEN clause and, either the record fails to match any of them, or all fields are null.
No records are discarded if an INTO TABLE clause is specified without a WHEN clause. An attempt is made to insert every record into such a table. Therefore, records may be rejected, but none are discarded.
Case Study 7: Extracting Data from a Formatted Report provides an example of using a discard file.
Data from LOBFILEs and SDFs is not written to a discard file when there are discarded rows.
You can limit the number of records to be discarded for each datafile by specifying an integer:
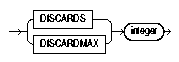
Text description of the illustration discard2.gif
When the discard limit (specified with integer) is reached, processing of the datafile terminates and continues with the next datafile, if one exists.
You can specify a different number of discards for each datafile. Or, if you specify the number of discards only once, then the maximum number of discards specified applies to all files.
If you specify a maximum number of discards, but no discard filename, SQL*Loader creates a discard file with the default filename and file extension or file type.
SQL*Loader supports different character encoding schemes (called character sets, or code pages). SQL*Loader uses features of Oracle's globalization support technology to handle the various single-byte and multibyte character encoding schemes available today.
In general, loading shift-sensitive character data can be much slower than loading simple ASCII or EBCDIC data. The fastest way to load shift-sensitive character data is to use fixed-position fields without delimiters. To improve performance, remember the following points:
The following sections provide a brief introduction to some of the supported character encoding schemes.
Multibyte character sets support Asian languages. Data can be loaded in multibyte format, and database object names (fields, tables, and so on) can be specified with multibyte characters. In the control file, comments and object names can also use multibyte characters.
SQL*Loader supports loading data that is in a Unicode character set.
Unicode is a universal encoded character set that supports storage of information from most languages in a single character set. Unicode provides a unique code value for every character, regardless of the platform, program, or language. There are two different encodings for Unicode, UTF-16 and UTF-8.
The UTF-16 Unicode encoding is a fixed-width multibyte encoding in which the character codes 0x0000 through 0x007F have the same meaning as the single-byte ASCII codes 0x00 through 0x7F.
The UTF-8 Unicode encoding is a variable-width multibyte encoding in which the character codes 0x00 through 0x7F have the same meaning as ASCII. A character in UTF-8 can be 1 byte, 2 bytes, or 3 bytes long.
See Also:
|
The Oracle database server uses the database character set for data stored in SQL CHAR datatypes (CHAR, VARCHAR2, CLOB, and LONG), for identifiers such as table names, and for SQL statements and PL/SQL source code. Only single-byte character sets and varying-width character sets that include either ASCII or EBCDIC characters are supported as database character sets. Multibyte fixed-width character sets (for example, AL16UTF16) are not supported as the database character set.
An alternative character set can be used in the database for data stored in SQL NCHAR datatypes (NCHAR, NVARCHAR, and NCLOB). This alternative character set is called the database national character set. Only Unicode character sets are supported as the database national character set.
By default, the datafile is in the character set as defined by the NLS_LANG parameter. The datafile character sets supported with NLS_LANG are the same as those supported as database character sets. SQL*Loader supports all Oracle-supported character sets in the datafile (even those not supported as database character sets).
For example, SQL*Loader supports multibyte fixed-width character sets (such as AL16UTF16 and JA16EUCFIXED) in the datafile. SQL*Loader also supports UTF-16 encoding with little endian byte ordering. However, the Oracle database server supports only UTF-16 encoding with big endian byte ordering (AL16UTF16) and only as a database national character set, not as a database character set.
The character set of the datafile can be set up by using the NLS_LANG parameter or by specifying a SQL*Loader CHARACTERSET parameter.
The default character set for all datafiles, if the CHARACTERSET parameter is not specified, is the session character set defined by the NLS_LANG parameter. The character set used in input datafiles can be specified with the CHARACTERSET parameter.
SQL*Loader has the capacity to automatically convert data from the datafile character set to the database character set or the database national character set, when they differ.
When data character set conversion is required, the target character set should be a superset of the source datafile character set. Otherwise, characters that have no equivalent in the target character set are converted to replacement characters, often a default character such as a question mark (?). This causes loss of data.
The sizes of the database character types CHAR and VARCHAR2 can be specified in bytes (byte-length semantics) or in characters (character-length semantics). If they are specified in bytes, and data character set conversion is required, the converted values may take more bytes than the source values if the target character set uses more bytes than the source character set for any character that is converted. This will result in the following error message being reported if the larger target value exceeds the size of the database column:
ORA-01401: inserted value too large for column
You can avoid this problem by specifying the database column size in characters and by also using character sizes in the control file to describe the data. Another way to avoid this problem is to ensure that the maximum column size is large enough, in bytes, to hold the converted value.
See Also:
|
Specifying the CHARACTERSET parameter tells SQL*Loader the character set of the input datafile. The default character set for all datafiles, if the CHARACTERSET parameter is not specified, is the session character set defined by the NLS_LANG parameter. Only character data (fields in the SQL*Loader datatypes CHAR, VARCHAR, VARCHARC, numeric EXTERNAL, and the datetime and interval datatypes) is affected by the character set of the datafile.
The CHARACTERSET syntax is as follows:
CHARACTERSET char_set_name
The char_set_name variable specifies the character set name. Normally, the specified name must be the name of an Oracle-supported character set.
For UTF-16 Unicode encoding, use the name UTF16 rather than AL16UTF16. AL16UTF16, which is the supported Oracle character set name for UTF-16 encoded data, is only for UTF-16 data that is in big endian byte order. However, because you are allowed to set up data using the byte order of the system where you create the datafile, the data in the datafile can be either big endian or little endian. Therefore, a different character set name (UTF16) is used. The character set name AL16UTF16 is also supported. But if you specify AL16UTF16 for a datafile that has little endian byte order, SQL*Loader issues a warning message and processes the datafile as big endian.
The CHARACTERSET parameter can be specified for primary datafiles as well as LOBFILEs and SDFs. It is possible to specify different character sets for different input datafiles. A CHARACTERSET parameter specified before the INFILE parameter applies to the entire list of primary datafiles. If the CHARACTERSET parameter is specified for primary datafiles, the specified value will also be used as the default for LOBFILEs and SDFs. This default setting can be overridden by specifying the CHARACTERSET parameter with the LOBFILE or SDF specification.
The character set specified with the CHARACTERSET parameter does not apply to data in the control file (specified with INFILE). To load data in a character set other than the one specified for your session by the NLS_LANG parameter, you must place the data in a separate datafile.
See Also:
|
The SQL*Loader control file itself is assumed to be in the character set specified for your session by the NLS_LANG parameter. If the control file character set is different from the datafile character set, keep the following issue in mind. Delimiters and comparison clause values specified in the SQL*Loader control file as character strings are converted from the control file character set to the datafile character set before any comparisons are made. To ensure that the specifications are correct, you may prefer to specify hexadecimal strings, rather than character string values.
If hexadecimal strings are used with a datafile in the UTF-16 Unicode encoding, the byte order is different on a big endian versus a little endian system. For example, "," (comma) in UTF-16 on a big endian system is X'002c'. On a little endian system it is X'2c00'. SQL*Loader requires that you always specify hexadecimal strings in big endian format. If necessary, SQL*Loader swaps the bytes before making comparisons. This allows the same syntax to be used in the control file on both a big endian and a little endian system.
Record terminators for datafiles that are in stream format in the UTF-16 Unicode encoding default to "\n" in UTF-16 (that is, 0x000A on a big endian system and 0x0A00 on a little endian system). You can override these default settings by using the "STR 'char_str'" or the "STR x'hex_str'" specification on the INFILE line. For example, you could use either of the following to specify that 'ab' is to be used as the record terminator, instead of '\n'.
INFILE myfile.dat "STR 'ab'" INFILE myfile.dat "STR x'00410042'"
Any data included after the BEGINDATA statement is also assumed to be in the character set specified for your session by the NLS_LANG parameter.
For the SQL*Loader datatypes (CHAR, VARCHAR, VARCHARC, DATE, and EXTERNAL numerics), SQL*Loader supports lengths of character fields that are specified in either bytes (byte-length semantics) or characters (character-length semantics). For example, the specification CHAR(10) in the control file can mean 10 bytes or 10 characters. These are equivalent if the datafile uses a single-byte character set. However, they are often different if the datafile uses a multibyte character set.
To avoid insertion errors caused by expansion of character strings during character set conversion, use character-length semantics in both the datafile and the target database columns.
Byte-length semantics are the default for all datafiles except those that use the UTF16 character set (which uses character-length semantics by default). To override the default you can specify CHAR or CHARACTER, as shown in the following syntax:
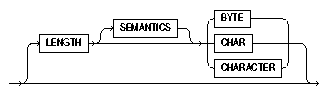
Text description of the illustration char_length.gif
The LENGTH parameter is placed after the CHARACTERSET parameter in the SQL*Loader control file. The LENGTH parameter applies to the syntax specification for primary datafiles as well as to LOBFILEs and secondary datafiles (SDFs). It is possible to specify different length semantics for different input datafiles. However, a LENGTH specification before the INFILE parameters applies to the entire list of primary datafiles. The LENGTH specification specified for the primary datafile is used as the default for LOBFILEs and SDFs. You can override that default by specifying LENGTH with the LOBFILE or SDF specification. Unlike the CHARACTERSET parameter, the LENGTH parameter can also apply to data contained within the control file itself (that is, INFILE * syntax).
You can specify CHARACTER instead of CHAR for the LENGTH parameter.
If character-length semantics are being used for a SQL*Loader datafile, then the following SQL*Loader datatypes will use character-length semantics:
For the VARCHAR datatype, the length subfield is still a binary SMALLINT length subfield, but its value indicates the length of the character string in characters.
The following datatypes use byte-length semantics even if character-length semantics are being used for the datafile, because the data is binary, or is in a special binary-encoded form in the case of ZONED and DECIMAL:
INTEGERSMALLINTFLOATDOUBLEBYTEINTZONEDDECIMALRAWVARRAWVARRAWCGRAPHICGRAPHIC EXTERNALVARGRAPHICThe start and end arguments to the POSITION parameter are interpreted in bytes, even if character-length semantics are in use in a datafile. This is necessary to handle datafiles that have a mix of data of different datatypes, some of which use character-length semantics, and some of which use byte-length semantics. It is also needed to handle position with the VARCHAR datatype, which has a SMALLINT length field and then the character data. The SMALLINT length field takes up a certain number of bytes depending on the system (usually 2 bytes), but its value indicates the length of the character string in characters.
Character-length semantics in the datafile can be used independent of whether or not character-length semantics are used for the database columns. Therefore, the datafile and the database columns can use either the same or different length semantics.
Loads are interrupted and discontinued for a number of reasons. A primary reason is space errors, in which SQL*Loader runs out of space for data rows or index entries. A load might also be discontinued because the maximum number of errors was exceeded, an unexpected error was returned to SQL*Loader from the server, a record was too long in the datafile, or a Control+C was executed.
The behavior of SQL*Loader when a load is discontinued varies depending on whether it is a conventional path load or a direct path load, and on the reason the load was interrupted. Additionally, when an interrupted load is continued, the use and value of the SKIP parameter can vary depending on the particular case. The following sections explain the possible scenarios.
In a conventional path load, data is committed after all data in the bind array is loaded into all tables. If the load is discontinued, only the rows that were processed up to the time of the last commit operation are loaded. There is no partial commit of data.
In a direct path load, the behavior of a discontinued load varies depending on the reason the load was discontinued.
If there is one INTO TABLE statement in the control file and a space error occurs, the following scenarios can take place:
ROWS parameter was specified.ROWS has been specified. In that case, all data that was previously committed will be saved.If there are multiple INTO TABLE statements in the control file and a space error occurs on one of those tables, the following scenarios can take place:
ROWS parameter was specified. In this scenario, a different number of rows could be loaded into each table; to continue the load you would need to specify a different value for the SKIP parameter for every table. SQL*Loader only reports the value for the SKIP parameter if it is the same for all tables.ROWS has been specified. In that case, all data that was previously committed is saved, and when you continue the load the value you supply for the SKIP parameter will be the same for all tables.If the maximum number of errors is exceeded, SQL*Loader stops loading records into any table and the work done to that point is committed. This means that when you continue the load, the value you specify for the SKIP parameter may be different for different tables. SQL*Loader only reports the value for the SKIP parameter if it is the same for all tables.
If a fatal error is encountered, the load is stopped and no data is saved unless ROWS was specified at the beginning of the load. In that case, all data that was previously committed is saved. SQL*Loader only reports the value for the SKIP parameter if it is the same for all tables.
If SQL*Loader is in the middle of saving data when a Control+C is issued, it continues to do the save and then stops the load after the save completes. Otherwise, SQL*Loader stops the load without committing any work that was not committed already. This means that the value of the SKIP parameter will be the same for all tables.
When a load is discontinued, any data already loaded remains in the tables, and the tables are left in a valid state. If the conventional path is used, all indexes are left in a valid state.
If the direct path load method is used, any indexes that run out of space are left in an unusable state. You must drop these indexes before the load can continue. You can re-create the indexes either before continuing or after the load completes.
Other indexes are valid if no other errors occurred. See Indexes Left in an Unusable State for other reasons why an index might be left in an unusable state.
The SQL*Loader log file tells you the state of the tables and indexes and the number of logical records already read from the input datafile. Use this information to resume the load where it left off.
When SQL*Loader must discontinue a direct path or conventional path load before it is finished, some rows have probably already been committed or marked with savepoints. To continue the discontinued load, use the SKIP parameter to specify the number of logical records that have already been processed by the previous load. At the time the load is discontinued, the value for SKIP is written to the log file in a message similar to the following:
Specify SKIP=1001 when continuing the load.
This message specifying the value of the SKIP parameter is preceded by a message indicating why the load was discontinued.
Note that for multiple-table loads, the value of the SKIP parameter is displayed only if it is the same for all tables.
Because Oracle9i supports user-defined record sizes larger than 64 KB (see READSIZE (read buffer size)), the need to break up logical records into multiple physical records is reduced. However, there may still be situations in which you may want to do so. At some point, when you want to combine those multiple physical records back into one logical record, you can use one of the following clauses, depending on your data:
Use CONCATENATE when you want SQL*Loader to always combine the same number of physical records to form one logical record. In the following example, integer specifies the number of physical records to combine.
CONCATENATE integer
The integer value specified for CONCATENATE determines the number of physical record structures that SQL*Loader allocates for each row in the column array. Because the default value for COLUMNARRAYROWS is large, if you also specify a large value for CONCATENATE, then excessive memory allocation can occur. If this happens, you can improve performance by reducing the value of the COLUMNARRAYROWS parameter to lower the number of rows in a column array.
Use CONTINUEIF if the number of physical records to be continued varies. The parameter CONTINUEIF is followed by a condition that is evaluated for each physical record, as it is read. For example, two records might be combined if a pound sign (#) were in byte position 80 of the first record. If any other character were there, the second record would not be added to the first.
The full syntax for CONTINUEIF adds even more flexibility:

Text description of the illustration cont_if.gif
Table 5-2 describes the parameters for CONTINUEIF.
|
Note: The positions in the |
If the PRESERVE parameter is not used, the continuation field is removed from all physical records when the logical record is assembled. That is, data values are allowed to span the records with no extra characters (continuation characters) in the middle.
If the PRESERVE parameter is used, the continuation field is kept in all physical records when the logical record is assembled.
Example 5-2 through Example 5-5 show the use of CONTINUEIF THIS and CONTINUEIF NEXT, with and without the PRESERVE parameter.
Assume that you have physical records 14 bytes long and that a period represents a space:
%%aaaaaaaa.... %%bbbbbbbb.... ..cccccccc.... %%dddddddddd.. %%eeeeeeeeee.. ..ffffffffff..
In this example, the CONTINUEIF THIS clause does not use the PRESERVE parameter:
CONTINUEIF THIS (1:2) = '%%'
Therefore, the logical records are assembled as follows:
aaaaaaaa....bbbbbbbb....cccccccc.... dddddddddd..eeeeeeeeee..ffffffffff..
Note that columns 1 and 2 (for example, %% in physical record 1) are removed from the physical records when the logical records are assembled.
Assume that you have the same physical records as in Example 5-2.
In this example, the CONTINUEIF THIS clause uses the PRESERVE parameter:
CONTINUEIF THIS PRESERVE (1:2) = '%%'
Therefore, the logical records are assembled as follows:
%%aaaaaaaa....%%bbbbbbbb......cccccccc.... %%dddddddddd..%%eeeeeeeeee....ffffffffff..
Note that columns 1 and 2 are not removed from the physical records when the logical records are assembled.
Assume that you have physical records 14 bytes long and that a period represents a space:
..aaaaaaaa.... %%bbbbbbbb.... %%cccccccc.... ..dddddddddd.. %%eeeeeeeeee.. %%ffffffffff..
In this example, the CONTINUEIF NEXT clause does not use the PRESERVE parameter:
CONTINUEIF NEXT (1:2) = '%%'
Therefore, the logical records are assembled as follows (the same results as for Example 5-2).
aaaaaaaa....bbbbbbbb....cccccccc.... dddddddddd..eeeeeeeeee..ffffffffff..
Assume that you have the same physical records as in Example 5-4.
In this example, the CONTINUEIF NEXT clause uses the PRESERVE parameter:
CONTINUEIF NEXT PRESERVE (1:2) = '%%'
Therefore, the logical records are assembled as follows:
..aaaaaaaa....%%bbbbbbbb....%%cccccccc.... ..dddddddddd..%%eeeeeeeeee..%%ffffffffff..
| See Also:
Case Study 4: Loading Combined Physical Records for an example of the |
This section describes the way in which you specify:
The INTO TABLE clause of the LOAD DATA statement allows you to identify tables, fields, and datatypes. It defines the relationship between records in the datafile and tables in the database. The specification of fields and datatypes is described in later sections.
Among its many functions, the INTO TABLE clause allows you to specify the table into which you load data. To load multiple tables, you include one INTO TABLE clause for each table you wish to load.
To begin an INTO TABLE clause, use the keywords INTO TABLE, followed by the name of the Oracle table that is to receive the data.
The syntax is as follows:
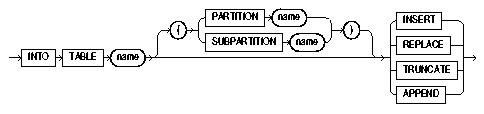
Text description of the illustration intotab.gif
The table must already exist. The table name should be enclosed in double quotation marks if it is the same as any SQL or SQL*Loader reserved keyword, if it contains any special characters, or if it is case sensitive.
INTO TABLE scott."CONSTANT" INTO TABLE scott."Constant" INTO TABLE scott."-CONSTANT"
The user must have INSERT privileges for the table being loaded. If the table is not in the user's schema, then the user must either use a synonym to reference the table or include the schema name as part of the table name (for example, scott.emp).
When you are loading a table, you can use the INTO TABLE clause to specify a table-specific loading method (INSERT, APPEND, REPLACE, or TRUNCATE) that applies only to that table. That method overrides the global table-loading method. The global table-loading method is INSERT, by default, unless a different method was specified before any INTO TABLE clauses. The following sections discuss using these options to load data into empty and nonempty tables.
If the tables you are loading into are empty, use the INSERT option.
This is SQL*Loader's default method. It requires the table to be empty before loading. SQL*Loader terminates with an error if the table contains rows. Case Study 1: Loading Variable-Length Data provides an example.
If the tables you are loading into already contain data, you have three options:
APPENDREPLACETRUNCATE
|
Note: This section corresponds to the DB2 keyword |
If data already exists in the table, SQL*Loader appends the new rows to it. If data does not already exist, the new rows are simply loaded. You must have SELECT privilege to use the APPEND option. Case Study 3: Loading a Delimited, Free-Format File provides an example.
With REPLACE, all rows in the table are deleted and the new data is loaded. The table must be in your schema, or you must have DELETE privilege on the table. Case Study 4: Loading Combined Physical Records provides an example.
The row deletes cause any delete triggers defined on the table to fire. If DELETE CASCADE has been specified for the table, then the cascaded deletes are carried out. For more information on cascaded deletes, see the information about data integrity in Oracle9i Database Concepts.
The REPLACE method is a table replacement, not a replacement of individual rows. SQL*Loader does not update existing records, even if they have null columns. To update existing rows, use the following procedure:
UPDATE statement with correlated subqueries.For more information, see the UPDATE statement in Oracle9i SQL Reference.
The SQL TRUNCATE statement quickly and efficiently deletes all rows from a table or cluster, to achieve the best possible performance. For the TRUNCATE statement to operate, the table's referential integrity constraints must first be disabled. If they have not been disabled, SQL*Loader returns an error.
Once the integrity constraints have been disabled, DELETE CASCADE is no longer defined for the table. If the DELETE CASCADE functionality is needed, then the contents of the table must be manually deleted before the load begins.
The table must be in your schema, or you must have the DROP ANY TABLE privilege.
| See Also:
Oracle9i Database Administrator's Guide for more information about the |
The OPTIONS parameter can be specified for individual tables in a parallel load. (It is only valid for a parallel load.)
The syntax for the OPTIONS parameter is as follows:

Text description of the illustration intotab3.gif
You can choose to load or discard a logical record by using the WHEN clause to test a condition in the record.
The WHEN clause appears after the table name and is followed by one or more field conditions. The syntax for field_condition is as follows:
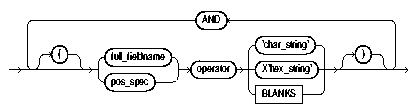
Text description of the illustration fld_cond.gif
For example, the following clause indicates that any record with the value "q" in the fifth column position should be loaded:
WHEN (5) = 'q'
A WHEN clause can contain several comparisons, provided each is preceded by AND. Parentheses are optional, but should be used for clarity with multiple comparisons joined by AND, for example:
WHEN (deptno = '10') AND (job = 'SALES')
See Also:
|
If a record with a LOBFILE or SDF is discarded, SQL*Loader skips the corresponding data in that LOBFILE or SDF.
If all data fields are terminated similarly in the datafile, you can use the FIELDS clause to indicate the default delimiters. The syntax for the fields_spec, termination_spec, and enclosure_spec clauses is as follows:

Text description of the illustration fields.gif
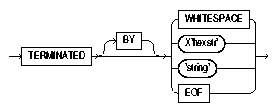
Text description of the illustration terminat.gif
|
Note: Terminator strings can contain one or more characters. Also, |

Text description of the illustration enclose.gif
You can override the delimiter for any given column by specifying it after the column name. Case Study 3: Loading a Delimited, Free-Format File provides an example.
See Also:
|
When the control file definition specifies more fields for a record than are present in the record, SQL*Loader must determine whether the remaining (specified) columns should be considered null or whether an error should be generated.
If the control file definition explicitly states that a field's starting position is beyond the end of the logical record, then SQL*Loader always defines the field as null. If a field is defined with a relative position (such as dname and loc in the following example), and the record ends before the field is found, then SQL*Loader could either treat the field as null or generate an error. SQL*Loader uses the presence or absence of the TRAILING NULLCOLS clause (shown in the following syntax diagram) to determine the course of action.

Text description of the illustration intotab6.gif
Text description of the illustration intotab7.gif
The TRAILING NULLCOLS clause tells SQL*Loader to treat any relatively positioned columns that are not present in the record as null columns.
For example, consider the following data:
10 Accounting
Assume that the preceding data is read with the following control file and the record ends after dname:
INTO TABLE dept TRAILING NULLCOLS ( deptno CHAR TERMINATED BY " ", dname CHAR TERMINATED BY WHITESPACE, loc CHAR TERMINATED BY WHITESPACE )
In this case, the remaining loc field is set to null. Without the TRAILING NULLCOLS clause, an error would be generated due to missing data.
| See Also:
Case Study 7: Extracting Data from a Formatted Report for an example of |
This section describes the following SQL*Loader options that control how index entries are created:
The SORTED INDEXES clause applies to direct path loads. It tells SQL*Loader that the incoming data has already been sorted on the specified indexes, allowing SQL*Loader to optimize performance.
The SINGLEROW option is intended for use during a direct path load with APPEND on systems with limited memory, or when loading a small number of records into a large table. This option inserts each index entry directly into the index, one record at a time.
By default, SQL*Loader does not use SINGLEROW to append records to a table. Instead, index entries are put into a separate, temporary storage area and merged with the original index at the end of the load. This method achieves better performance and produces an optimal index, but it requires extra storage space. During the merge, the original index, the new index, and the space for new entries all simultaneously occupy storage space.
With the SINGLEROW option, storage space is not required for new index entries or for a new index. The resulting index may not be as optimal as a freshly sorted one, but it takes less space to produce. It also takes more time because additional UNDO information is generated for each index insert. This option is suggested for use when either of the following situations exists:
Multiple INTO TABLE clauses allow you to:
In the first case, it is common for the INTO TABLE clauses to refer to the same table. This section illustrates the different ways to use multiple INTO TABLE clauses and shows you how to use the POSITION parameter.
Some data storage and transfer media have fixed-length physical records. When the data records are short, more than one can be stored in a single, physical record to use the storage space efficiently.
In this example, SQL*Loader treats a single physical record in the input file as two logical records and uses two INTO TABLE clauses to load the data into the emp table. For example, assume the data is as follows:
1119 Smith 1120 Yvonne 1121 Albert 1130 Thomas
The following control file extracts the logical records:
INTO TABLE emp (empno POSITION(1:4) INTEGER EXTERNAL, ename POSITION(6:15) CHAR) INTO TABLE emp (empno POSITION(17:20) INTEGER EXTERNAL, ename POSITION(21:30) CHAR)
The same record could be loaded with a different specification. The following control file uses relative positioning instead of fixed positioning. It specifies that each field is delimited by a single blank (" ") or with an undetermined number of blanks and tabs (WHITESPACE):
INTO TABLE emp (empno INTEGER EXTERNAL TERMINATED BY " ", ename CHAR TERMINATED BY WHITESPACE) INTO TABLE emp (empno INTEGER EXTERNAL TERMINATED BY " ", ename CHAR) TERMINATED BY WHITESPACE)
The important point in this example is that the second empno field is found immediately after the first ename, although it is in a separate INTO TABLE clause. Field scanning does not start over from the beginning of the record for a new INTO TABLE clause. Instead, scanning continues where it left off.
To force record scanning to start in a specific location, you use the POSITION parameter. That mechanism is described in Distinguishing Different Input Record Formats and in Loading Data into Multiple Tables.
A single datafile might contain records in a variety of formats. Consider the following data, in which emp and dept records are intermixed:
1 50 Manufacturing -- DEPT record 2 1119 Smith 50 -- EMP record 2 1120 Snyder 50 1 60 Shipping 2 1121 Stevens 60
A record ID field distinguishes between the two formats. Department records have a 1 in the first column, while employee records have a 2. The following control file uses exact positioning to load this data:
INTO TABLE dept WHEN recid = 1 (recid FILLER POSITION(1:1) INTEGER EXTERNAL, deptno POSITION(3:4) INTEGER EXTERNAL, dname POSITION(8:21) CHAR) INTO TABLE emp WHEN recid <> 1 (recid FILLER POSITION(1:1) INTEGER EXTERNAL, empno POSITION(3:6) INTEGER EXTERNAL, ename POSITION(8:17) CHAR, deptno POSITION(19:20) INTEGER EXTERNAL)
The records in the previous example could also be loaded as delimited data. In this case, however, it is necessary to use the POSITION parameter. The following control file could be used:
INTO TABLE dept WHEN recid = 1 (recid FILLER INTEGER EXTERNAL TERMINATED BY WHITESPACE, deptno INTEGER EXTERNAL TERMINATED BY WHITESPACE, dname CHAR TERMINATED BY WHITESPACE) INTO TABLE emp WHEN recid <> 1 (recid FILLER POSITION(1) INTEGER EXTERNAL TERMINATED BY ' ', empno INTEGER EXTERNAL TERMINATED BY ' ' ename CHAR TERMINATED BY WHITESPACE, deptno INTEGER EXTERNAL TERMINATED BY ' ')
The POSITION parameter in the second INTO TABLE clause is necessary to load this data correctly. It causes field scanning to start over at column 1 when checking for data that matches the second format. Without it, SQL*Loader would look for the recid field after dname.
A single datafile may contain records made up of row objects inherited from the same base row object type. For example, consider the following simple object type and object table definitions in which a nonfinal base object type is defined along with two object subtypes that inherit from the base type:
CREATE TYPE person_t AS OBJECT (name VARCHAR2(30), age NUMBER(3)) not final; CREATE TYPE employee_t UNDER person_t (empid NUMBER(5), deptno NUMBER(4), dept VARCHAR2(30)) not final; CREATE TYPE student_t UNDER person_t (stdid NUMBER(5), major VARCHAR2(20)) not final; CREATE TABLE persons OF person_t;
The following input datafile contains a mixture of these row objects subtypes. A type ID field distinguishes between the three subtypes. person_t objects have a P in the first column, employee_t objects have an E, and student_t objects have an S.
P,James,31, P,Thomas,22, E,Pat,38,93645,1122,Engineering, P,Bill,19, P,Scott,55, S,Judy,45,27316,English, S,Karen,34,80356,History, E,Karen,61,90056,1323,Manufacturing, S,Pat,29,98625,Spanish, S,Cody,22,99743,Math, P,Ted,43, E,Judy,44,87616,1544,Accounting, E,Bob,50,63421,1314,Shipping, S,Bob,32,67420,Psychology, E,Cody,33,25143,1002,Human Resources,
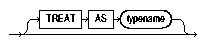
The following control file uses relative positioning based on the POSITION parameter to load this data. Note the use of the TREAT AS clause with a specific object type name. This informs SQL*Loader that all input row objects for the object table will conform to the definition of the named object type.
INTO TABLE persons REPLACE WHEN typid = 'P' TREAT AS person_t FIELDS TERMINATED BY "," (typid FILLER POSITION(1) CHAR, name CHAR, age CHAR) INTO TABLE persons REPLACE WHEN typid = 'E' TREAT AS employee_t FIELDS TERMINATED BY "," (typid FILLER POSITION(1) CHAR, name CHAR, age CHAR, empid CHAR, deptno CHAR, dept CHAR) INTO TABLE persons REPLACE WHEN typid = 'S' TREAT AS student_t FIELDS TERMINATED BY "," (typid FILLER POSITION(1) CHAR, name CHAR, age CHAR, stdid CHAR, major CHAR)
| See Also:
Loading Column Objects for more information on loading object types |
By using the POSITION clause with multiple INTO TABLE clauses, data from a single record can be loaded into multiple normalized tables. See Case Study 5: Loading Data into Multiple Tables.
Multiple INTO TABLE clauses allow you to extract multiple logical records from a single input record and recognize different record formats in the same file.
For delimited data, proper use of the POSITION parameter is essential for achieving the expected results.
When the POSITION parameter is not used, multiple INTO TABLE clauses process different parts of the same (delimited data) input record, allowing multiple tables to be loaded from one record. When the POSITION parameter is used, multiple INTO TABLE clauses can process the same record in different ways, allowing multiple formats to be recognized in one input file.
SQL*Loader uses the SQL array-interface option to transfer data to the database. Multiple rows are read at one time and stored in the bind array. When SQL*Loader sends the Oracle database an INSERT command, the entire array is inserted at one time. After the rows in the bind array are inserted, a COMMIT is issued.
The determination of bind array size pertains to SQL*Loader's conventional path option. It does not apply to the direct path load method because a direct path load uses the direct path API, rather than Oracle's SQL interface.
| See Also:
Oracle Call Interface Programmer's Guide for more information about the concepts of direct path loading |
The bind array must be large enough to contain a single row. If the maximum row length exceeds the size of the bind array, as specified by the BINDSIZE parameter, SQL*Loader generates an error. Otherwise, the bind array contains as many rows as can fit within it, up to the limit set by the value of the ROWS parameter.
The BINDSIZE and ROWS parameters are described in Command-Line Parameters.
Although the entire bind array need not be in contiguous memory, the buffer for each field in the bind array must occupy contiguous memory. If the operating system cannot supply enough contiguous memory to store a field, SQL*Loader generates an error.
Large bind arrays minimize the number of calls to the Oracle database server and maximize performance. In general, you gain large improvements in performance with each increase in the bind array size up to 100 rows. Increasing the bind array size to be greater than 100 rows generally delivers more modest improvements in performance. The size (in bytes) of 100 rows is typically a good value to use.
In general, any reasonably large size permits SQL*Loader to operate effectively. It is not usually necessary to perform the detailed calculations described in this section. Read this section when you need maximum performance or an explanation of memory usage.
When you specify a bind array size using the command-line parameter BINDSIZE (see BINDSIZE (maximum size)) or the OPTIONS clause in the control file (see OPTIONS Clause), you impose an upper limit on the bind array. The bind array never exceeds that maximum.
As part of its initialization, SQL*Loader determines the size in bytes required to load a single row. If that size is too large to fit within the specified maximum, the load terminates with an error.
SQL*Loader then multiplies that size by the number of rows for the load, whether that value was specified with the command-line parameter ROWS (see ROWS (rows per commit)) or the OPTIONS clause in the control file (see OPTIONS Clause).
If that size fits within the bind array maximum, the load continues--SQL*Loader does not try to expand the number of rows to reach the maximum bind array size. If the number of rows and the maximum bind array size are both specified, SQL*Loader always uses the smaller value for the bind array.
If the maximum bind array size is too small to accommodate the initial number of rows, SQL*Loader uses a smaller number of rows that fits within the maximum.
The bind array's size is equivalent to the number of rows it contains times the maximum length of each row. The maximum length of a row is equal to the sum of the maximum field lengths, plus overhead, as follows:
bind array size = (number of rows) * ( SUM(fixed field lengths) + SUM(maximum varying field lengths) + ( (number of varying length fields) * (size of length indicator) ) )
Many fields do not vary in size. These fixed-length fields are the same for each loaded row. For these fields, the maximum length of the field is the field size, in bytes, as described in SQL*Loader Datatypes. There is no overhead for these fields.
The fields that can vary in size from row to row are:
CHARDATEINTERVAL DAY TO SECONDINTERVAL DAY TO YEARLONG VARRAWEXTERNALTIMETIMESTAMPTIME WITH TIME ZONETIMESTAMP WITH TIME ZONEVARCHARVARCHARCVARGRAPHICVARRAWVARRAWCThe maximum length of these datatypes is described in SQL*Loader Datatypes. The maximum lengths describe the number of bytes that the fields can occupy in the input data record. That length also describes the amount of storage that each field occupies in the bind array, but the bind array includes additional overhead for fields that can vary in size.
When the character datatypes (CHAR, DATE, and numeric EXTERNAL) are specified with delimiters, any lengths specified for these fields are maximum lengths. When specified without delimiters, the size in the record is fixed, but the size of the inserted field may still vary, due to whitespace trimming. So internally, these datatypes are always treated as varying-length fields--even when they are fixed-length fields.
A length indicator is included for each of these fields in the bind array. The space reserved for the field in the bind array is large enough to hold the longest possible value of the field. The length indicator gives the actual length of the field for each row.
|
Note: In conventional path loads, LOBFILEs are not included when allocating the size of a bind array. |
On most systems, the size of the length indicator is 2 bytes. On a few systems, it is 3 bytes. To determine its size, use the following control file:
OPTIONS (ROWS=1) LOAD DATA INFILE * APPEND INTO TABLE DEPT (deptno POSITION(1:1) CHAR(1)) BEGINDATA a
This control file loads a 1-byte CHAR using a 1-row bind array. In this example, no data is actually loaded because a conversion error occurs when the character a is loaded into a numeric column (deptno). The bind array size shown in the log file, minus one (the length of the character field) is the value of the length indicator.
Table 5-3 through Table 5-6 summarize the memory requirements for each datatype. "L" is the length specified in the control file. "P" is precision. "S" is the size of the length indicator. For more information on these values, see SQL*Loader Datatypes.
.| Datatype | Default Size | Length Specified with POSITION |
Length Specified with DATATYPE |
|---|---|---|---|
|
|
None |
L |
2*L |
|
|
None |
L - 2 |
2*(L-2) |
|
|
4Kb*2 |
L+S |
(2*L)+S |
| Datatype | Default Size | Maximum Length Specified (L) |
|---|---|---|
|
|
4Kb |
L+S |
|
|
255 |
L+S |
|
datetime and interval (delimited) |
255 |
L+S |
|
numeric |
255 |
L+S |
Pay particular attention to the default sizes allocated for VARCHAR, VARGRAPHIC, and the delimited forms of CHAR, DATE, and numeric EXTERNAL fields. They can consume enormous amounts of memory--especially when multiplied by the number of rows in the bind array. It is best to specify the smallest possible maximum length for these fields. Consider the following example:
CHAR(10) TERMINATED BY ","
With byte-length semantics, this example uses (10 + 2) * 64 = 768 bytes in the bind array, assuming that the length indicator is 2 bytes long and that 64 rows are loaded at a time.
With character-length semantics, the same example uses ((10 * s) + 2) * 64 bytes in the bind array, where "s" is the maximum size in bytes of a character in the datafile character set.
Now consider the following example:
CHAR TERMINATED BY ","
Regardless of whether byte-length semantics or character-length semantics are used, this example uses (255 + 2) * 64 = 16,448 bytes, because the default maximum size for a delimited field is 255 bytes. This can make a considerable difference in the number of rows that fit into the bind array.
When calculating a bind array size for a control file that has multiple INTO TABLE clauses, calculate as if the INTO TABLE clauses were not present. Imagine all of the fields listed in the control file as one, long data structure--that is, the format of a single row in the bind array.
If the same field in the data record is mentioned in multiple INTO TABLE clauses, additional space in the bind array is required each time it is mentioned. It is especially important to minimize the buffer allocations for such fields.
|
Note: Generated data is produced by the SQL*Loader functions |
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

