| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|





|
View PDF |
| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|
|
View PDF |
This chapter explains why performance data gathering is important, and it describes how to use available Oracle tools.
This chapter contains the following sections:
Effective data collection and analysis is essential for identifying and correcting system performance problems. Oracle provides a number of tools that allow a performance engineer to gather information regarding instance and database performance.
BSTAT/ESTAT, with significantly increased functionality over the BSTAT/ESTAT tool.To effectively diagnose a performance problem, it is vital to have an established performance baseline for later comparison when the system is running poorly. Without a baseline data point, it can be very difficult to identify new problems. For example, perhaps the volume of transactions on the system has increased, or the transaction profile or application has changed, or the number of users has increased.
Although Oracle Enterprise Manager, Statspack and BSTAT/ESTAT, and the V$ views have different interfaces (GUI, command line, SQL), the majority of data they collect and report on is extracted from the V$ views. Because the V$ views are based on memory-resident data, when an instance is shut down, the data related to the instance is lost.
In order to perform analysis of data from one day to the next, data visible through the V$ views must be saved. On each instance startup, the memory resident V$ views are reinitialized; hence, to determine what has changed within any particular period, you must calculate the difference in the performance data. This is done by subtracting the statistic values at the beginning of the period from the statistic values at the end of the period. This gives you the activity of the instance during that period, or the delta.The delta of each statistic can then be normalized (for example, over seconds or over transactions).
The delta of all statistics for a period of time can be considered a baseline, assuming the response time and operations performed on the instance were representative of some typical load on your system (that is, batch, online, or both).
Each of the tools Oracle provides (except for the V$ views themselves) has a mechanism for saving this data and for determining the delta.
It is also important to gather operating system and network statistics. These can then be correlated with the Oracle performance data. If you are using Statspack, BSTAT/ESTAT, or your own tool, you should devise a mechanism for collecting operating system statistics. With Oracle Enterprise Manager, this capability is built-in.
When initially examining performance data, you can formulate potential theories by examining your statistics. One way to ensure that your interpretation of the statistics is correct is to perform cross-checks with other data. This establishes whether a statistic or event is really of interest.
Some pitfalls are discussed in the following sections:
When tuning, it is common to compute a ratio that helps determine whether there is a problem. Such ratios include the buffer cache hit ratio, the soft-parse ratio, and the latch hit ratio. These ratios should not be used as 'hard and fast' identifiers of whether there is or is not a performance bottleneck. Rather, they should be used as indicators. In order to identify whether there is a bottleneck, other related evidence should be examined.
Setting TIMED_STATISTICS to true at the instance level directs the Oracle server to gather wait time for events, in addition to wait counts already available. This data is useful for comparing the total wait time for an event to the total elapsed time between the performance data collections. For example, if the wait event accounts for only 30 seconds out of a two hour period, then there is probably little to be gained by investigating this event, even though it may be the highest ranked wait event when ordered by time waited. However, if the event accounts for 30 minutes of a 45 minute period, then the event is worth investigating.
When looking at statistics, it is important to consider other factors that influence whether the statistic is of value. Such factors include the user load and the hardware capability. Even an event that had a wait of 30 minutes in a 45 minute snapshot might not be indicative of a problem if you discover that there were 2000 users on the system, and the host hardware was a 64 node machine.
If TIMED_STATISTICS is false, then the amount of time waited for an event is not available. Therefore, it is only possible to order wait events by the number of times each event was waited for. Although the events with the largest number of waits might indicate the potential bottleneck, they might not be the main bottleneck. This can happen when an event is waited for a large number of times, but the total time waited for that event is small. The converse is also true: an event with fewer waits might be a problem if the wait time is a significant proportion of the total wait time. Without having the wait times to use for comparison, it is difficult to determine whether a wait event is really of interest.
Oracle uses some wait events to indicate if the Oracle server process is idle. Typically, these events are of no value when investigating performance problems, and they should be ignored when examining the wait events.
When interpreting computed statistics (such as rates, statistics normalized over transactions, or ratios), it is important to cross-verify the computed statistic with the actual statistic counts. This confirms whether the derived rates are really of interest: small statistic counts usually can discount an unusual ratio. For example, on initial examination, a soft-parse ratio of 50% generally indicates a potential tuning area. If, however, there was only one hard parse and one soft parse during the data collection interval, then the soft-parse ratio would be 50%, even though the statistic counts show this is not an area of concern. In this case, the ratio is not of interest due to the low raw statistic counts.
| See Also:
"Setting the Level of Statistics Collection" for information about |
Oracle Enterprise Manager (EM) Diagnostics Pack captures related operating system, middle-tier, and application performance data, in addition to instance performance data, allowing end-to-end diagnostics.
The Diagnostics Pack can automatically analyze this performance data, display it in a graphical interface, and use alerts to immediately direct you to any performance problems. You can be alerted automatically through email or page when a problem is detected. Oracle Enterprise Manager also includes an integrated diagnostics methodology that uses guided drilldowns and expert advice to help you quickly resolve performance issues. Figure 20-1 is a screen of the Oracle Performance Manager.
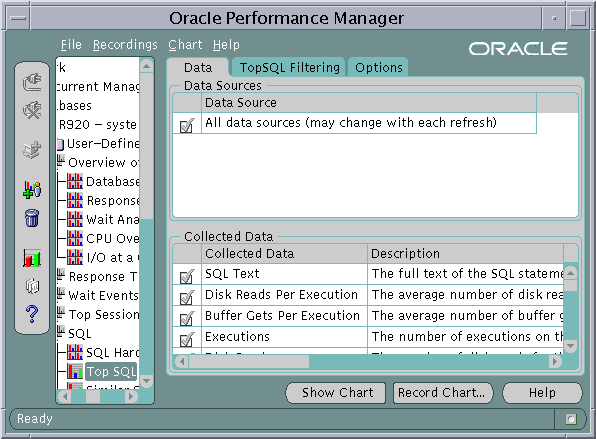
Text description of the illustration emperfmgr1.gif
EM also lets you store the captured data in a separate performance repository database. You can store the performance data for multiple databases in the same repository.
The EM Intelligent Agent data gathering service collects performance data on a scheduled basis. A single agent can manage the data collections for all Oracle databases and the operating system of the target node. The data is automatically stored in an historical data repository for performance reporting. Data stored in the repository can be used to analyze many facets of database performance, such as database load, cache allocations and efficiency, resource contention, and high-impact SQL.
Performance data collections can be initiated directly from the EM Console or through the Capacity Planner application of the Oracle Enterprise Manager Diagnostics Pack. HTML reports of historical performance data can be generated from the EM Console. These reports provide a comprehensive analysis of database system usage and performance, which can be easily accessed and navigated from a browser. EM also provides a graphical real-time Performance Overview for monitoring a subset of these performance metrics using line charts, bar graphs, and so forth.
The Performance Overview charts let you troubleshoot existing performance problems by drilling into performance data to track down the source of a performance bottleneck. For example, a decline in the memory sort percentage can be immediately investigated by drilling down to the sessions and corresponding SQL responsible for high volume sort activity. High-impact SQL statements discovered through this process can be further investigated by launching SQL diagnostic tools in the context of the problem.
Statspack fundamentally differs from the well known UTLBSTAT/UTLESTAT tuning scripts by collecting more information, and by storing the performance statistics data permanently in Oracle tables, which can later be used for reporting and analysis. The data collected can be analyzed using the report provided, which includes an instance health and load summary page, high resource SQL statements, as well as the traditional wait events and initialization parameters.
The V$ views are the performance information sources used by all Oracle performance tuning tools. The V$ views are based on memory structures initialized at instance startup. The memory structures, and the views that represent them, are automatically maintained by Oracle throughout the life of the instance.
If you choose not to use an Oracle tool to gather your performance data, then you need to develop your own. You need to save data from the required performance views to a structure on disk, so that the data can be analyzed and compared with other data collected. Because there are multiple collections, you need a key to identify each collection. This method is very similar to the method used by Statspack.
The following is an example of how to save performance data from a single V$ view to an Oracle table. To implement your own collection tool, you must perform a similar collection mechanism for all essential V$ views.
The following example creates a table that stores the collection data. The table has all V$FILESTAT columns and also includes the collection ID column and the collection date column. A sample SQL statement that reports the delta in this table for the first two collections has also been included.
Create the table, and insert the first data collection:
CREATE TABLE coll_filestat AS SELECT 1 coll_id -- collection number , sysdate coll_date -- collection date , fs.* FROM V$FILESTAT fs; ALTER TABLE coll_filestat add (CONSTRAINT coll_filestat PRIMARY KEY (coll_id, file#));
At the end of the interval, insert second collection:
INSERT INTO coll_filestat SELECT 2 -- collection number , sysdate -- collection date , fs.* FROM V$FILESTAT fs;
To query for high I/O tablespaces:
SELECT t.tablespace_name , SUM(fs2.phyrds-fs1.phyrds) / MAX(86400*(fs2.coll_date-fs1.coll_date)) "Rd/sec" , SUM(fs2.phyblkrd-fs1.phyblkrd) / MAX(86400*(fs2.coll_date-fs1.coll_date)) "Blk/sec" , SUM(fs2.phywrts-fs1.phywrts) / MAX(86400*(fs2.coll_date-fs1.coll_date)) "Wr/sec" , SUM(fs2.phyblkwrt-fs1.phyblkwrt) / MAX(86400*(fs2.coll_date-fs1.coll_date)) "Blk/sec" FROM coll_filestat fs1, coll_filestat fs2, dba_data_files t WHERE fs2.file# = fs1.file# AND fs2.coll_id = fs1.coll_id + 1 AND t.file_id = fs2.file# GROUP BY t.tablespace_name ORDER BY sum(fs2.phyblkrd+fs2.phyblkwrt-fs1.phyblkrd-fs1.phyblkwrt) DESC;
The following is a sample output from the preceding select statement:
TABLESPACE_N Rd/sec Blk/sec Wr/sec Blk/sec ------------ ------ ------- ------ ------- AP_T_02 287.1 2245.7 .0 .0 PO_T_01 313.5 650.6 .2 .2 RECEIVABLE_T 401.0 613.8 2.4 2.4 INV_T_01 154.3 155.3 .0 .0 APPLSYS_T_01 63.3 139.6 .4 .4 PA_T_01 102.3 102.3 .0 .0 SO_I_01 63.4 63.4 34.5 34.5 TEMP 2.3 45.0 1.9 47.0 RECEIVABLE_I 73.0 73.0 .1 .1 AP_T_03 69.3 69.3 .0 .0 RECEIVABLE_I 65.1 65.1 1.9 1.9 SO_T_01 54.0 57.8 2.9 2.9 SYSTEM 45.2 59.0 .3 .3 PER_T_01 48.0 58.7 .0 .0 AP_T_01 12.9 51.0 .2 .2 SO_T_03 43.0 43.0 1.2 1.2 PER_I_01 30.8 30.8 .0 .0 FA_T_01 22.3 22.3 .0 .0 INV_I_01 20.7 20.7 .7 .7 PO_I_01 19.5 19.5 .7 .7 GSR_T_01 19.2 19.2 .4 .4 INV_I_03 18.3 18.3 .0 .0 ROLL_01 1.4 1.4 14.7 14.7 PA_I_01 14.3 14.3 .2 .2
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

