Release 2 (9.2)
Part Number A96524-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Database Concepts Release 2 (9.2) Part Number A96524-01 |
|
This chapter describes the parallel execution of SQL statements. The topics in this chapter include:
|
Note: The parallel execution features described in this chapter are available only if you have purchased the Oracle9i Enterprise Edition. See Oracle9i Database New Features for information about Oracle9i Enterprise Edition. |
When Oracle runs SQL statements in parallel, multiple processes work together simultaneously to run a single SQL statement. By dividing the work necessary to run a statement among multiple processes, Oracle can run the statement more quickly than if only a single process ran it. This is called parallel execution or parallel processing.
Parallel execution dramatically reduces response time for data-intensive operations on large databases typically associated with decision support systems (DSS) and data warehouses. Symmetric multiprocessing (SMP), clustered systems, and massively parallel systems (MPP) gain the largest performance benefits from parallel execution because statement processing can be split up among many CPUs on a single Oracle system. You can also implement parallel execution on certain types of online transaction processing (OLTP) and hybrid systems.
Parallelism is the idea of breaking down a task so that, instead of one process doing all of the work in a query, many processes do part of the work at the same time. An example of this is when 12 processes handle 12 different months in a year instead of one process handling all 12 months by itself. The improvement in performance can be quite high.
Parallel execution helps systems scale in performance by making optimal use of hardware resources. If your system's CPUs and disk controllers are already heavily loaded, you need to alleviate the system's load or increase these hardware resources before using parallel execution to improve performance.
Some tasks are not well-suited for parallel execution. For example, many OLTP operations are relatively fast, completing in mere seconds or fractions of seconds, and the overhead of utilizing parallel execution would be large, relative to the overall execution time.
| See Also:
Oracle9i Data Warehousing Guide for specific information on tuning your parameter files and database to take full advantage of parallel execution |
During business hours, most OLTP systems should probably not use parallel execution. During off-hours, however, parallel execution can effectively process high-volume batch operations. For example, a bank can use parallelized batch programs to perform the millions of updates required to apply interest to accounts.
The most common example of using parallel execution is for DSS. Complex queries, such as those involving joins or searches of very large tables, are often best run in parallel.
Parallel execution is useful for many types of operations that access significant amounts of data. Parallel execution improves performance for:
Parallel execution benefits systems that have all of the following characteristics:
If your system lacks any of these characteristics, parallel execution might not significantly improve performance. In fact, parallel execution can reduce system performance on overutilized systems or systems with insufficient I/O bandwidth.
| See Also:
Oracle9i Data Warehousing Guide for further information regarding when to implement parallel execution |
Parallel execution is not normally useful for:
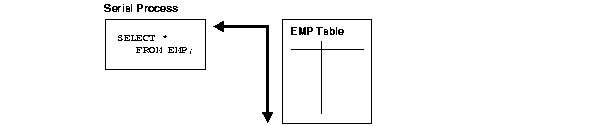
When parallel execution is not used, a single server process performs all necessary processing for the sequential execution of a SQL statement. For example, to perform a full table scan (such as SELECT * FROM employees), one process performs the entire operation, as illustrated in Figure 18-1.
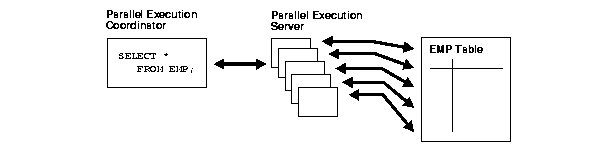
Parallel execution performs these operations in parallel using multiple parallel processes. One process, known as the parallel execution coordinator, dispatches the execution of a statement to several parallel execution servers and coordinates the results from all of the server processes to send the results back to the user.
Figure 18-2 illustrates several parallel execution servers performing a scan of the table employees. The table is divided dynamically (dynamic partitioning) into load units called granules and each granule is read by a single parallel execution server. The granules are generated by the coordinator. Each granule is a range of physical blocks of the table employees. The mapping of granules to execution servers is not static, but is determined at execution time. When an execution server finishes reading the rows of the table employees corresponding to a granule, it gets another granule from the coordinator if there are any granules remaining. This continues till all granules are exhausted, in other words. the entire table employees has been read. The parallel execution servers send results back to the parallel execution coordinator, which assembles the pieces into the desired full table scan.
Given a query plan for a SQL query, the parallel execution coordinator breaks down each operator in a SQL query into parallel pieces, runs them in the right order as specified in the query, and then integrates the partial results produced by the parallel execution servers executing the operators. The number of parallel execution servers assigned to a single operation is the degree of parallelism (DOP) for an operation. Multiple operations within the same SQL statement all have the same degree of parallelism.
See Also:
|
Each SQL statement undergoes an optimization and parallelization process when it is parsed. Therefore, when the data changes, if a more optimal execution plan or parallelization plan becomes available, Oracle can automatically adapt to the new situation.
After the optimizer determines the execution plan of a statement, the parallel execution coordinator determines the parallelization method for each operation in the execution plan. The coordinator must decide whether an operation can be performed in parallel and, if so, how many parallel execution servers to enlist. The number of parallel execution servers used for an operation is the degree of parallelism.
To illustrate intra-operation parallelism and inter-operation parallelism, consider the following statement:
SELECT * FROM employees ORDER BY employee_id;
The execution plan implements a full scan of the employees table followed by a sorting of the retrieved rows based on the value of the employee_id column. For the sake of this example, assume the last_name column is not indexed. Also assume that the degree of parallelism for the query is set to four, which means that four parallel execution servers can be active for any given operation.
Each of the two operations (scan and sort) performed concurrently is given its own set of parallel execution servers. Therefore, both operations have parallelism. Parallelization of an individual operation where the same operation is performed on smaller sets of rows by parallel execution servers achieves what is termed intra-operation parallelism. When two operations run concurrently on different sets of parallel execution servers with data flowing from one operation into the other, we achieve what is termed inter-operation parallelism.
Due to the producer/consumer nature of the Oracle server's operations, only two operations in a given tree need to be performed simultaneously to minimize execution time.
Figure 18-3 illustrates the parallel execution of our sample query.
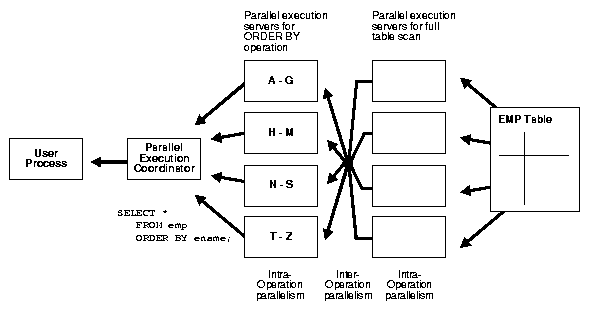
As you can see from Figure 18-3, there are actually eight parallel execution servers involved in the query even though the degree of parallelism is four. This is because a parent and child operator can be performed at the same time (inter-operation parallelism).
Also note that all of the parallel execution servers involved in the scan operation send rows to the appropriate parallel execution server performing the sort operation. If a row scanned by a parallel execution server contains a value for the ename column between A and G, that row gets sent to the first ORDER BY parallel execution server. When the scan operation is complete, the sorting processes can return the sorted results to the coordinator, which in turn returns the complete query results to the user.
The parallel execution coordinator may enlist two or more of the instance's parallel execution servers to process a SQL statement. The number of parallel execution servers associated with a single operation is known as the degree of parallelism.
Note that the degree of parallelism applies directly only to intra-operation parallelism. If inter-operation parallelism is possible, the total number of parallel execution servers for a statement can be twice the specified degree of parallelism. No more than two sets of parallel execution servers can run simultaneously. Each set of parallel execution servers may process multiple operations. Only two sets of parallel execution servers need to be active to guarantee optimal inter-operation parallelism.
Parallel execution is designed to effectively use multiple CPUs and disks to answer queries quickly. When multiple users use parallel execution at the same time, it is easy to quickly exhaust available CPU, memory, and disk resources.
Oracle provides several ways to manage resource utilization in conjunction with parallel execution environments, including:
PARALLEL_ADAPTIVE_MULTI_USER parameter of the ALTER SYSTEM statement or in your initialization parameter file.See Also:
|
As an example of parallel query with intra- and inter-operation parallelism, consider a more complex query:
SELECT /*+ PARALLEL(employees 4) PARALLEL(departments 4) USE_HASH(employees) ORDERED */ MAX(salary), AVG(salary) FROM employees, departments WHERE employees.department_id = departments.department_id GROUP BY employees.department_id;
Note that hints have been used in the query to force the join order and join method, and to specify the degree of parallelism (DOP) of the tables employees and departments. In general, you should let the optimizer determine the order and method.
The query plan or data flow graph corresponding to this query is illustrated in Figure 18-4.
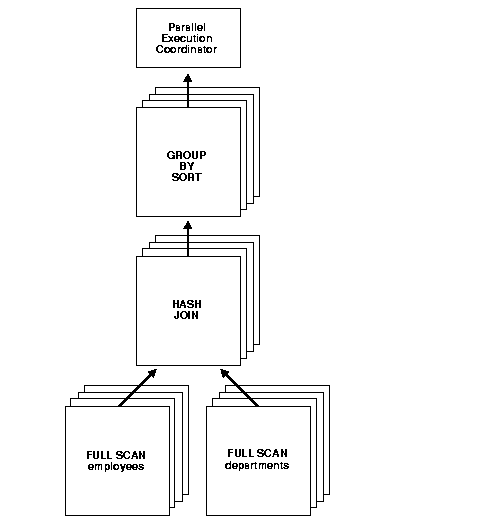
Given two sets of parallel execution servers SS1 and SS2, the execution of this plan will proceed as follows: each server set (SS1 and SS2) will have four execution processes because of the PARALLEL hint in the query that specifies the DOP. In other words, the DOP will be four because each set of parallel execution servers will have four processes.
Slave set SS1 first scans the table employees while SS2 will fetch rows from SS1 and build a hash table on the rows. In other words, the parent servers in SS2 and the child servers in SS2 work concurrently: one in scanning employees in parallel, the other in consuming rows sent to it from SS1 and building the hash table for the hash join in parallel. This is an example of inter-operation parallelism.
After SS1 has finished scanning the entire table employees (that is, all granules or task units for employees are exhausted), it scans the table departments in parallel. It sends its rows to servers in SS2, which then perform the probes to finish the hash-join in parallel. After SS1 is done scanning the table departments in parallel and sending the rows to SS2, it switches to performing the GROUP BY in parallel. This is how two server sets run concurrently to achieve inter-operation parallelism across various operators in the query tree while achieving intra-operation parallelism in executing each operation in parallel.
Another important aspect of parallel execution is the re-partitioning of rows while they are sent from servers in one server set to another. For the query plan in Figure 18-4, after a server process in SS1 scans a row of employees, which server process of SS2 should it send it to? The partitioning of rows flowing up the query tree is decided by the operator into which the rows are flowing into. In this case, the partitioning of rows flowing up from SS1 performing the parallel scan of employees into SS2 performing the parallel hash-join is done by hash partitioning on the join column value. That is, a server process scanning employees computes a hash function of the value of the column employees.employee_id to decide the number of the server process in SS2 to send it to. The partitioning method used in parallel queries is explicitly shown in the EXPLAIN PLAN of the query. Note that the partitioning of rows being sent between sets of execution servers should not be confused with Oracle's partitioning feature whereby tables can be partitioned using hash, range, and other methods.
| See Also:
Oracle9i Data Warehousing Guide for examples of using |
Most operations can be parallelized. The following are commonly parallelized to improve performance:
| See Also:
Oracle9i Data Warehousing Guide for specific information regarding restrictions for parallel DML as well as some considerations to keep in mind when designing a warehouse |
You can parallelize queries and subqueries in SELECT statements, as well as the query portions of DDL statements and DML statements (INSERT, UPDATE, and DELETE). However, you cannot parallelize the query portion of a DDL or DML statement if it references a remote object. When you issue a parallel DML or DDL statement in which the query portion references a remote object, the operation is automatically run serially.
| See Also:
Oracle9i SQL Reference for information about the syntax and restrictions for parallel query statements |
You can normally use parallel DDL where you use regular DDL. There are, however, some additional details to consider when designing your database. One important restriction is that parallel DDL cannot be used on tables with object or LOB columns.
You can parallelize the CREATE TABLE AS SELECT, CREATE INDEX, and ALTER INDEX REBUILD statements. If the table is partitioned, you can parallelize ALTER TABLE MOVE or [SPLIT or COALESCE] statements as well. You can also use parallelism for ALTER INDEX REBUILD [or SPLIT] when the index is partitioned.
All of these DDL operations can be performed in NOLOGGING mode for either parallel or serial execution.
The CREATE TABLE statement for an index-organized table can be parallelized either with or without an AS SELECT clause.
Different parallelism is used for different operations. Parallel create (partitioned) table as select and parallel create (partitioned) index run with a degree of parallelism equal to the number of partitions.
Parallel operations require accurate statistics to perform optimally.
See Also:
|
Parallel DML (parallel insert, update, and delete) uses parallel execution mechanisms to speed up or scale up large DML operations against large database tables and indexes. You can also use INSERT ... SELECT statements to insert rows into multiple tables as part of a single DML statement. You can normally use parallel DML where you use regular DML.
Although data manipulation language (DML) normally includes queries, the term parallel DML refers only to inserts, updates, upserts and deletes done in parallel.
See Also:
|
You can parallelize the use of SQL*Loader, where large amounts of data are routinely encountered. To speed up your loads, you can use a parallel direct-path load as in the following example:
SQLLOAD USERID=SCOTT/TIGER CONTROL=LOAD1.CTL DIRECT=TRUE PARALLEL=TRUE SQLLOAD USERID=SCOTT/TIGER CONTROL=LOAD2.CTL DIRECT=TRUE PARALLEL=TRUE SQLLOAD USERID=SCOTT/TIGER CONTROL=LOAD3.CTL DIRECT=TRUE PARALLEL=TRUE
You can also use a parameter file to achieve the same thing.
An important point to remember is that indexes are not maintained during a parallel load.
| See Also:
Oracle9i Database Utilities for information about the syntax and restrictions for parallel loading |
The way you make a statement run in parallel depends upon the type of parallel operation. The three types of parallel operation are:
To achieve parallelism for SQL query statements, one or more of the tables being scanned should have a parallel attribute.
To achieve parallelism for SQL DDL statements, the parallel clause should be specified.
Due to the differences in locking between serial and parallel DML, you must explicitly enable parallel DML before you can use it. To achieve parallelism for SQL DML statements, you must first enable parallel DML in your session:
ALTER SESSION ENABLE PARALLEL DML;
Then any DML issued against a table with a parallel attribute will occur in parallel, if no PDML restrictions are violated. For example:
INSERT INTO mytable SELECT * FROM origtable;
See Also:
|
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

