| Oracle9i XML Database Developer's Guide - Oracle XML DB Release 2 (9.2) Part Number A96620-02 |
|





|
View PDF |
| Oracle9i XML Database Developer's Guide - Oracle XML DB Release 2 (9.2) Part Number A96620-02 |
|
|
View PDF |
This chapter describes how to use the XMLType datatype, create and manipulate XMLType tables and columns, and query on them. It contains the following sections:
|
Note:
|
Oracle9i Release 1 (9.0.1) introduced a new datatype, XMLType, to facilitate native handling of XML data in the database. The following summarizes XMLType:
XMLType can be used in PL/SQL stored procedures as parameters, return values, and variables.XMLType can represent an XML document as an instance (of XMLType) in SQL.XMLType has built-in member functions that operate on XML content. For example, you can use XMLType functions to create, extract, and index XML data stored in Oracle9i database.With XMLType and these capabilities, SQL developers can leverage the power of the relational database while working in the context of XML. Likewise, XML developers can leverage the power of XML standards while working in the context of a relational database.
XMLType datatype can be used as the datatype of columns in tables and views. Variables of XMLType can be used in PL/SQL stored procedures as parameters, return values, and so on. You can also use XMLType in SQL, PL/SQL, and Java (through JDBC).
A number of useful functions that operate on XML content are provided. Many of these are provided as both SQL and member functions of XMLType. For example, the extract() function extracts a specific node(s) from an XMLType instance.
You can use XMLType in SQL queries in the same way as any other user-defined datatypes in the system.
See Also:
|
The XMLType datatype and API provides significant advantages. It enables SQL operations on XML content, as well as XML operations on SQL content:
XMLType has a versatile API for application development, as it includes built-in functions, indexing support, navigation, and so on.XMLType in SQL statements combined with other columns and datatypes. For example, you can query XMLType columns and join the result of the extraction with a relational column, and then Oracle can determine an optimal way to execute these queries.XMLType is optimized to not materialize the XML data into a tree structure unless needed. Therefore when SQL selects XMLType instances inside queries, only a serialized form is exchanged across function boundaries. These are exploded into tree format only when operations such as extract() and existsNode() are performed. The internal structure of XMLType is also an optimized DOM-like tree structure.XMLType columns. You can also create function-based indexes on existsNode() and extract() functions to speed up query evaluation.
Use XMLType when you need to perform the following:
existsNode() and extract() provide the necessary SQL query functions over XML documents.extract() and existsNode() functions: Note that XMLType uses the built-in C XML parser and processor and hence provides better performance and scalability when used inside the server.XMLType has member functions that you can use to create function-based indexes to optimize searches.XMLType instead of CLOBs or relational storage allows applications to gracefully move to various storage alternatives later without affecting any of the query or DML statements in the application.XMLType. Since Oracle9i database is natively aware that XMLType can store XML data, better optimizations and indexing techniques can be done. By writing applications to use XMLType, these optimizations and enhancements can be easily achieved and preserved in future releases without your needing to rewrite applications.XMLType data can be stored in two ways or a combination thereof:
XMLType offers a CLOB storage option. In future releases, Oracle may provide other storage options, such as BLOBs, NCLOBS, and so on. You can also create a CLOB-based storage for XML schema-based storage.
When you create an XMLType column without any XML schema specification, a hidden CLOB column is automatically created to store the XML data. The XMLType column itself becomes a virtual column over this hidden CLOB column. It is not possible to directly access the CLOB column; however, you can set the storage characteristics for the column using the XMLType storage clause.
XMLType achieves DOM fidelity by maintaining information that SQL or Java objects normally do not provide for, such as:
Native XMLType instances contain hidden columns that store this extra information that does not quite fit in the SQL object model. This information can be accessed through APIs in SQL or Java, using member functions, such as extractNode().
Changing XMLType storage from structured storage to LOB, or vice versa, is possible using database IMPORT and EXPORT. Your application code does not have to change. You can then change XML storage options when tuning your application, since each storage option has its own benefits.
Table 4-1 summarizes some advantages and disadvantages to consider when selecting your Oracle XML DB storage option.
Use CLOB storage for XMLType in the following cases:
See Also:
|
Oracle9i Release 1 (9.0.1) introduced several SQL functions and XMLType member functions that operate on XMLType values. Oracle9i Release 2 (9.2) has expanded functionality. It provides several new SQL functions and XMLType member functions.
See Also:
|
All XMLType functions use the built-in C parser and processor to parse XML data, validate it, and apply XPath expressions on it. They also use an optimized in-memory DOM tree for processing, such as extracting XML documents or fragments.
You can use the XMLType API to create tables and columns. The createXML() static function of the XMLType API can be used to create XMLType instances for insertion. By storing your XML documents as XMLType, XML content can be readily searched using standard SQL queries.
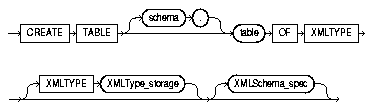
Figure 4-1 shows the syntax for creating an XMLType table:
CREATE TABLE [schema.] table OF XMLTYPE [XMLTYPE XMLType_storage] [XMLSchema_spec];
This section shows some simple examples of how to create an XMLType column and use it in a SQL statement, and how to create XMLType tables.
The following are examples of creating, adding, and dropping XMLType columns:
The XMLType column can be created like any other user-defined type column:
CREATE TABLE warehouses( warehouse_id NUMBER(4), warehouse_spec XMLTYPE, warehouse_name VARCHAR2(35), location_id NUMBER(4));
As explained, you can create XMLType columns by simply using the XMLType as the datatype. The following statement creates a purchase order document column, poDoc, of XMLType:
CREATE TABLE po_xml_tab( poid number, poDoc XMLTYPE); CREATE TABLE po_xtab of XMLType; -- this creates a table of XMLType. The default -- is CLOB based storage.
You can alter tables to add XMLType columns as well. This is similar to any other datatype. The following statement adds a new customer document column to the table:
ALTER TABLE po_xml_tab add (custDoc XMLType);
You can alter tables to drop XMLType columns, similar to any other datatype. The following statement drops column custDoc:
ALTER TABLE po_xml_tab drop (custDoc);
To insert values into the XMLType column, you need to bind an XMLType instance.
An XMLType instance can be easily created from a VARCHAR or a Character Large Object (CLOB) by using the XMLType() constructor:
INSERT INTO warehouses VALUES ( 100, XMLType( '<Warehouse whNo="100"> <Building>Owned</Building> </Warehouse>'), 'Tower Records', 1003);
This example creates an XMLType instance from a string literal. The input to createXML() can be any expression that returns a VARCHAR2 or CLOB. createXML() also checks that the input XML is well-formed.
The following simple SELECT statement shows how you can use XMLType in an SQL statement:
SELECT w.warehouse_spec.extract('/Warehouse/Building/text()').getStringVal() "Building" FROM warehouses w;
where warehouse_spec is an XMLType column operated on by member function extract(). The result of this simple query is a string (varchar2):
Building ----------------- Owned
An XML document in an XMLType can be stored packed in a CLOB. Then updates have to replace the whole document in place.
To update an XML document, you can execute a standard SQL UPDATE statement. You need to bind an XMLType instance, as follows:
UPDATE warehouses SET warehouse_spec = XMLType ('<Warehouse whono="200"> <Building>Leased</Building> </Warehouse>');
This example created an XMLType instance from a string literal and updates column warehouse_spec with the new value.
|
Note: Any triggers would get fired on the UPDATE statement You can see and modify the XML value inside the triggers. |
Deleting a row containing an XMLType column is no different from deleting a row containing any other datatype.
You can use extract() and existsNode() functions to identify rows to delete as well. For example to delete all warehouse rows for which the warehouse building is leased, you can write a statement such as:
DELETE FROM warehouses e WHERE e.warehouse_spec.extract('//Building/text()').getStringVal() = 'Leased';
The following are guidelines for storing XML data in XMLType tables and columns:
First, define a table/column of XMLType. You can include optional storage characteristics with the table/column definition.
|
Note: This release of Oracle supports creating tables of |
Use the XMLType constructor to create the XMLType instance before inserting into the column/table. You can also use a variety of other functions that return XMLType.
| See Also:
"SYS_XMLGEN(): Converting an XMLType Instance" , for an example. |
You can select out the XMLType instance from the column. XMLType also offers a choice of member functions, such as extract() and existsNode(), to extract a particular node and to check to see if a node exists respectively. See the table of XMLType member functions in Oracle9i XML API Reference - XDK and Oracle XML DB.
You can define an Oracle Text index on XMLType columns. This enables you to use CONTAINS, HASPATH, INPATH, and other text operators on the column. All the Oracle Text operators and index functions that operate on LOB columns also work on XMLType columns.
In this release, a new Oracle Text index type, CTXXPATH is introduced. This helps existsNode() implement indexing and optimizes the evaluation of existsNode() in a predicate.
XML data in an XMLType column can be stored as a CLOB column. Hence you can also specify LOB storage characteristics for that column. In example, "Creating XMLType: Creating XMLType Columns", the warehouse_spec column is an XMLType column.
You can specify storage characteristics on this column when creating the table as follows:
CREATE TABLE po_xml_tab( poid NUMBER(10), poDoc XMLTYPE ) XMLType COLUMN poDoc STORE AS CLOB ( TABLESPACE lob_seg_ts STORAGE (INITIAL 4096 NEXT 4096) CHUNK 4096 NOCACHE LOGGING );
The STORE AS clause is also supported when adding columns to a table.
To add a new XMLType column to this table and specify the storage clause for that column, you can use the following SQL statement:
ALTER TABLE po_xml_tab add( custDoc XMLTYPE ) XMLType COLUMN custDoc STORE AS CLOB ( TABLESPACE lob_seg_ts STORAGE (INITIAL 4096 NEXT 4096) CHUNK 4096 NOCACHE LOGGING );
In non- schema-based storage, you can use XMLDATA to change storage characteristics on an XMLType column.
For example, consider table foo_tab:
CREATE TABLE foo_tab (a xmltype);
To change the storage characteristics of LOB column a in foo_tab, you can use the following statement:
ALTER TABLE foo_tab MODIFY LOB (a.xmldata) (storage (next 5K) cache);
XMLDATA identifies the internal storage column. In the case of CLOB-based storage this corresponds to the CLOB column. The same holds for XML schema-based storage. You can use XMLDATA to explore structured storage and modify the values.
|
Note: In this release, the |
You can use the XMLDATA attribute in constraints and indexes, in addition to storage clauses.
| See also:
Oracle9i Application Developer's Guide - Large Objects (LOBs) f and Oracle9i SQL Reference for more information about LOB storage options |
You can specify NOT NULL constraint on an XMLType column.
CREATE TABLE po_xml_tab ( poid number(10), poDoc XMLType NOT NULL );
prevents inserts such as:
INSERT INTO po_xml_tab (poDoc) VALUES (null);
You can also use the ALTER TABLE statement to change NOT NULL information of an XMLType column, in the same way you would for other column types:
ALTER TABLE po_xml_tab MODIFY (poDoc NULL); ALTER TABLE po_xml_tab MODIFY (poDoc NOT NULL);
You can also define check constraints on XMLType columns. Other default values are not supported on this datatype.
Since XMLType is a user-defined data type with functions defined on it, you can invoke functions on XMLType and obtain results. You can use XMLType wherever you use a user-defined type, including for table columns, views, trigger bodies, and type definitions.
You can perform the following manipulations or Data Manipulation Language (DML) on XML data in XMLType columns and tables:
You can insert data into XMLType columns in the following ways:
XMLType columns can only store well-formed XML documents. Fragments and other non-well-formed XML cannot be stored in XMLType columns.
To use the INSERT statement to insert XML data into XMLType, you need to first create XML documents to perform the insert with. You can create the insertable XML documents as follows:
XMLType constructors. This can be done in SQL, PL/SQL, and Java.XMLElement(), XMLConcat(), and XMLAGG(). This can be done in SQL, PL/SQL, and Java.The following examples use INSERT...SELECT and the XMLType constructor to first create an XML document and then insert the document into the XMLType columns. Consider table po_clob_tab that contains a CLOB, poClob, for storing an XML document:
CREATE TABLE po_clob_tab ( poid number, poClob CLOB ); -- some value is present in the po_clob_tab INSERT INTO po_clob_tab VALUES(100, '<?xml version="1.0"?> <PO pono="1"> <PNAME>Po_1</PNAME> <CUSTNAME>John</CUSTNAME> <SHIPADDR> <STREET>1033, Main Street</STREET> <CITY>Sunnyvalue</CITY> <STATE>CA</STATE> </SHIPADDR> </PO>');
You can insert a purchase order XML document into table, po_xml_tab, by simply creating an XML instance from the CLOB data stored in the other po_clob_tab:
INSERT INTO po_xml_tab SELECT poid, XMLType(poClob) FROM po_clob_tab;
|
Note: You can also get the CLOB value from any expression, including functions that can create temporary CLOBs or select out CLOBs from other table or views. |
This example inserts a purchase order into table po_tab using the XMLType constructor:
INSERT INTO po_xml_tab VALUES(100, XMLType('<?xml version="1.0"?> <PO pono="1"> <PNAME>Po_1</PNAME> <CUSTNAME>John</CUSTNAME> <SHIPADDR> <STREET>1033, Main Street</STREET> <CITY>Sunnyvalue</CITY> <STATE>CA</STATE> </SHIPADDR> </PO>'));
This example inserts a purchase order into table po_xml_tab by generating it using the XMLElement() SQL function. Assume that the purchase order is an object view that contains a purchase order object. The whole definition of the purchase order view is given in "DBMS_XMLGEN: Generating a Purchase Order from the Database in XML Format".
INSERT INTO po_xml_tab SELECT XMLelement("po", value(p)) FROM po p WHERE p.pono=2001;
XMLElement() creates an XMLType from the purchase order object, which is then inserted into table po_xml_tab. You can also use SYS_XMLGEN() in the INSERT statement.
You can query XML data from XMLType columns in the following ways:
XMLType columns through SQL, PL/SQL, or JavaXMLType columns directly and using extract() and existsNode()SQL functions such as existsNode(), extract(), XMLTransform(), and updateXML() operate on XML data inside SQL. XMLType datatype supports most of these as member functions. You can use either the selfish style of invocation or the SQL functions.
You can select XMLType data using PL/SQL or Java. You can also use the getClobVal(), getStringVal(), or getNumberVal() functions to retrieve XML as a CLOB, VARCHAR, or NUMBER, respectively.
This example shows how to select an XMLType column using SQL*Plus:
SET long 2000 SELECT e.poDoc.getClobval() AS poXML FROM po_xml_tab e; POXML --------------------- <?xml version="1.0"?> <PO pono="2"> <PNAME>Po_2</PNAME> <CUSTNAME>Nance</CUSTNAME> <SHIPADDR> <STREET>2 Avocet Drive</STREET> <CITY>Redwood Shores</CITY> <STATE>CA</STATE> </SHIPADDR> </PO>
You can query XMLType data and extract portions of it using the existsNode() and extract() functions. Both these functions use a subset of the W3C XPath recommendation to navigate the document.
XPath is a W3C recommendation for navigating XML documents. XPath models the XML document as a tree of nodes. It provides a rich set of operations to "walk" the tree and to apply predicates and node test functions. Applying an XPath expression to an XML document can result in a set of nodes. For instance, /PO/PONO selects out all "PONO" child elements under the "PO" root element of the document.
Table 4-2 lists some common constructs used in XPath.
The XPath must identify a single or a set of element, text, or attribute nodes. The result of the XPath cannot be a boolean expression.
You can select XMLType data through PL/SQL, OCI, or Java. You can also use the getClobVal(), getStringVal(), or getNumberVal() functions to retrieve the XML as a CLOB, VARCHAR or a number, respectively.
This example shows how to select an XMLType column using getClobVal() and existsNode():
set long 2000 SELECT e.poDoc.getClobval() AS poXML FROM po_xml_tab e WHERE e.poDoc.existsNode('/PO[PNAME = "po_2"]') = 1; POXML --------------------- <?xml version="1.0"?> <PO pono="2"> <PNAME>Po_2</PNAME> <CUSTNAME>Nance</CUSTNAME> <SHIPADDR> <STREET>2 Avocet Drive</STREET> <CITY>Redwood Shores</CITY> <STATE>CA</STATE> </SHIPADDR>
</PO>
The syntax for the existsNode() function is described in Figure 4-2 and also as follows:
existsNode(XMLType_instance IN XMLType, XPath_string IN VARCHAR2, namespace_string IN varchar2 := null) RETURN NUMBER

existsNode() function on XMLType checks if the given XPath evaluation results in at least a single XML element or text node. If so, it returns the numeric value 1, otherwise, it returns a 0. Namespace can be used to identify the mapping of prefix(es) specified in the XPath_string to the corresponding namespace(s).
For example, consider an XML document such as:
<PO> <PONO>100</PONO> <PNAME>Po_1</PNAME> <CUSTOMER CUSTNAME="John"/> <SHIPADDR> <STREET>1033, Main Street</STREET> <CITY>Sunnyvalue</CITY> <STATE>CA</STATE> </SHIPADDR> </PO>
An XPath expression such as /PO/PNAME results in a single node. Therefore, existsNode() will return 1 for that XPath. This is the same with /PO/PNAME/text(), which results in a single text node.
An XPath expression such as /PO/POTYPE does not return any nodes. Therefore, an existsNode() on this would return the value 0.
To summarize, existsNode() member function can be used in queries and to create function-based indexes to speed up evaluation of queries.
The following example tests for the existence of the /Warehouse/Dock node in the warehouse_spec column XML path of the sample table oe.warehouses:
SELECT warehouse_id, EXISTSNODE(warehouse_spec, '/Warehouse/Docks') "Loading Docks" FROM warehouses WHERE warehouse_spec IS NOT NULL; WAREHOUSE_ID Loading Docks ------------ ------------- 1 1 2 1 3 0 4 1
You can create function-based indexes using existsNode() to speed up the execution. You can also create a CTXXPATH index to help speed up arbitrary XPath searching.
The extract() function is similar to the existsNode() function. It applies a VARCHAR2 XPath string with an optional namespace parameter and returns an XMLType instance containing an XML fragment. The syntax is described in Figure 4-3 and as follows:
extract(XMLType_instance IN XMLType, XPath_string IN VARCHAR2, namespace_string In varchar2 := null) RETURN XMLType;
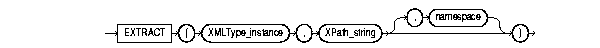
extract() on XMLType extracts the node or a set of nodes from the document identified by the XPath expression. The extracted nodes can be elements, attributes, or text nodes. When extracted out, all text nodes are collapsed into a single text node value. Namespace can be used to supply namespace information for prefixes in the XPath string.
The XMLType resulting from applying an XPath through extract() need not be a well-formed XML document but can contain a set of nodes or simple scalar data in some cases. You can use the getStringVal() or getNumberVal() methods on XMLType to extract this scalar data.
For example, the XPath expression /PO/PNAME identifies the PNAME element inside the XML document shown previously. The expression /PO/PNAME/text(), on the other hand, refers to the text node of the PNAME element.
Use text() node test function to identify text nodes in elements before using the getStringVal() or getNumberVal() to convert them to SQL data. Not having the text() node would produce an XML fragment.
For example, XPath expressions:
/PO/PNAME identifies the fragment <PNAME>PO_1</PNAME>/PO/PNAME/text() identifies the text value "PO_1"You can use the index mechanism to identify individual elements in case of repeated elements in an XML document. For example, if you have an XML document such as:
<PO> <PONO>100</PONO> <PONO>200</PONO> </PO>
you can use:
//PONO[1] to identify the first "PONO" element (with value 100).//PONO[2] to identify the second "PONO" element (with value 200).The result of extract() is always an XMLType. If applying the XPath produces an empty set, then extract() returns a NULL value.
Hence, extract() member function can be used in a number of ways, including the following:
This example extracts the value of node, /Warehouse/Docks, of column, warehouse_spec in table oe.warehouses:
SELECT warehouse_name, extract(warehouse_spec, '/Warehouse/Docks').getStringVal() "Number of Docks" FROM warehouses WHERE warehouse_spec IS NOT NULL; WAREHOUSE_NAME Number of Docks -------------------- -------------------- Southlake, Texas <Docks>2</Docks> San Francisco <Docks>1</Docks> New Jersey <Docks/> Seattle, Washington <Docks>3</Docks>
The extractValue() function takes as arguments an XMLType instance and an XPath expression. It returns a scalar value corresponding to the result of the XPath evaluation on the XMLType instance. extractValue() syntax is also described in Figure 4-4.
VARCHAR2.VARCHAR2.extractValue() tries to infer the proper return type from the XML schema of the document. If the XMLType is non- schema-based or the proper return type cannot be determined, Oracle XML DB returns a VARCHAR2.
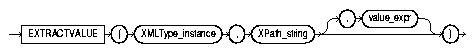
extractValue() permits you to extract the desired value more easily than when using the equivalent extract function. It is an ease-of-use and shortcut function. So instead of using:
extract(x,'path/text()').get(string|num)val()
you can replace extract().getStringVal() or extract().getnumberval() with extractValue() as follows:
extractValue(x, 'path/text()')
With extractValue() you can leave off the text(), but ONLY if the node pointed to by the 'path' part has only one child and that child is a text node. Otherwise, an error is thrown.
extractValue() syntax is the same as extract().
extractValue() has the following characteristics:
extractValue() can automatically return the appropriate datatype based on the XML schema information, if it can detect so at compile time of the query. For instance, if the XML schema information for the path /PO/POID indicates that this is a numerical value, then extractValue() returns a NUMBER.extractValue(xmlinstance, '/PO/PNAME')
extracts out the text child of PNAME. This is equivalent to:
extract(xmlinstance, '/PO/PNAME/text()').getstringval()
The following example takes as input the same arguments as the example for extract () Function. Instead of returning an XML fragment, as extract() does, it returns the scalar value of the XML fragment:
SELECT warehouse_name, extractValue(e.warehouse_spec, '/Warehouse/Docks') "Docks" FROM warehouses e WHERE warehouse_spec IS NOT NULL; WAREHOUSE_NAME Docks -------------------- ------------ Southlake, Texas 2 San Francisco 1 New Jersey Seattle, Washington 3
ExtractValue() automatically extracted out the text child of Docks element and returned that value. You can also write this using extract() as follows:
extract(e.warehouse_spec, '/Warehouse/Docks/text()').getstringval()
The following SQL examples illustrate ways you can query XML.
Assume the po_xml_tab table, which contains the purchase order identification and the purchase order XML columns, and assume that the following values are inserted into the table:
INSERT INTO po_xml_tab values (100, xmltype('<?xml version="1.0"?> <PO> <PONO>221</PONO> <PNAME>PO_2</PNAME> </PO>')); INSERT INTO po_xml_tab values (200, xmltype('<?xml version="1.0"?> <PO> <PONAME>PO_1</PONAME> </PO>'));
Now you can extract the numerical values for the purchase order numbers using extract():
SELECT e.poDoc.extract('//PONO/text()').getNumberVal() as pono FROM po_xml_tab e WHERE e.podoc.existsnode('/PO/PONO') = 1 AND poid > 1;
Here extract() extracts the contents of tag, purchase order number, "PONO". existsNode() finds nodes where "PONO" exists as a child of "PO".
|
Note: Here |
The following example shows how you can select out the XML data and query it inside PL/SQL: create a transient instance from the purchase order table and then perform some extraction on it. Assume po_xml_tab contains the data shown in Example 4-16, "Inserting XML Data Using XMLType() with String", modified:
set serverout on declare poxml XMLType; cust XMLType; val VARCHAR2(200); begin -- select the adt instance select poDoc into poxml from po_xml_tab p where p.poid = 100; -- do some traversals and print the output cust := poxml.extract('//SHIPADDR'); -- do something with the customer XML fragment val := cust.getStringVal(); dbms_output.put_line(' The customer XML value is '|| val); end; /
The following example shows how you can extract out data from an XML purchase order and insert it into an SQL relational table. Consider the following relational tables:
CREATE TABLE cust_tab ( custid number primary key, custname varchar2(20) ); INSERT INTO cust_tab values (1001, 'John Nike'); CREATE TABLE po_rel_tab ( pono number, pname varchar2(100), custid number references cust_tab, shipstreet varchar2(100), shipcity varchar2(30), shipzip varchar2(20) );
You can write a simple PL/SQL block to transform XML of the form:
<?xml version = '1.0'?> <PO> <PONO>2001</PONO> <PNAME>Po_1</PNAME> <CUSTOMER CUSTNAME="John Nike"/> <SHIPADDR> <STREET>323 College Drive</STREET> <CITY>Edison</CITY> <STATE>NJ</STATE> <ZIP>08820</ZIP> </SHIPADDR> </PO>
into the relational tables, using extract().
Here is an SQL example assuming that the XML described in the previous example is present in the po_xml_tab:
INSERT INTO po_rel_tab SELECT p.poDoc.extract('/PO/PONO/text()').getnumberval() as pono, p.poDoc.extract('/PO/PNAME/text()').getstringval() as pname, -- get the customer id corresponding to the customer name ( SELECT c.custid FROM cust_tab c WHERE c.custname = p.poDoc.extract('/PO/CUSTOMER/@CUSTNAME').getstringval() ) as custid, p.poDoc.extract('/PO/SHIPADDR/STREET/text()').getstringval() as shipstreetr, p.poDoc.extract('//CITY/text()').getstringval() as shipcity, p.poDoc.extract('//ZIP/text()').getstringval() as shipzip FROM po_xml_tab p;
Table po_tab should now have the following values:
PONO PNAME CUSTID SHIPSTREET SHIPCITY SHIPZIP ---------------------------------------------------------------- 2001 Po_1 1001 323 College Drive Edison 08820
|
Note:
|
You can do the same in an equivalent fashion inside a PL/SQL block, as follows:
DECLARE poxml XMLType; cname varchar2(200); pono number; pname varchar2(100); shipstreet varchar2(100); shipcity varchar2(30); shipzip varchar2(20); BEGIN -- select the adt instance SELECT poDoc INTO poxml FROM po_xml_tab p; cname := poxml.extract('//CUSTOMER/@CUSTNAME').getstringval(); pono := poxml.extract('/PO/PONO/text()').getnumberval(); pname := poxml.extract('/PO/PNAME/text()').getstringval(); shipstreet := poxml.extract('/PO/SHIPADDR/STREET/text()').getstringval(); shipcity := poxml.extract('//CITY/text()').getstringval(); shipzip := poxml.extract('//ZIP/text()').getstringval(); INSERT INTO po_rel_tab VALUES (pono, pname, (SELECT custid FROM cust_tab c WHERE custname = cname), shipstreet, shipcity, shipzip); END; /
Using extract() and existsNode() functions, you can perform a variety of search operations on the column, as follows:
SELECT e.poDoc.extract('/PO/PNAME/text()').getStringVal() PNAME FROM po_xml_tab e WHERE e.poDoc.existsNode('/PO/SHIPADDR') = 1 AND e.poDoc.extract('//PONO/text()').getNumberVal() = 300 AND e.poDoc.extract('//@CUSTNAME').getStringVal() like '%John%';
This SQL statement extracts the purchase order name "PNAME" from purchase order element PO, from all XML documents containing a shipping address with a purchase order number of 300, and a customer name "CUSTNAME" containing the string "John".
Using extractValue(), you can rewrite the preceding query as:
SELECT extractvalue(e.poDoc, '/PO/PNAME') PNAME FROM po_xml_tab e WHERE e.poDoc.existsNode('/PO/SHIPADDR') = 1 AND extractvalue(e.poDoc,'//PONO') = 300 AND extractvalue(e.poDoc,'//@CUSTNAME') like '%John%';
extract() member function extracts nodes identified by the XPath expression and returns an XMLType containing the fragment. Here, the result of the traversal may be a set of nodes, a singleton node, or a text value. You can check if the result is a fragment by using the isFragment() function on the XMLType. For example:
SELECT e.poDoc.extract('/PO/SHIPADDR/STATE').isFragment() FROM po_xml_tab e;
|
Note: You cannot insert fragments into |
The previous SQL statement returns 0, since the extraction /PO/SHIPADDR/STATE returns a singleton well-formed node which is not a fragment.
On the other hand, an XPath such as /PO/SHIPADDR/STATE/text() is considered a fragment, since it is not a well-formed XML document.
This section talks about updating transient XML instances and XML data stored in tables.
With CLOB-based storage, in this release, an update effectively replaces the whole document. Use the SQL UPDATE statement to update the whole XML document. The right hand side of the UPDATE's SET clause must be an XMLType instance. This can be created using the SQL functions and XML constructors that return an XML instance, or using the PL/SQL DOM APIs for XMLType or Java DOM API, that change and bind existing XML instances.
updateXML() function takes in a source XMLType instance, and a set of XPath value pairs. It returns a new XML instance consisting of the original XMLType instance with appropriate XML nodes updated with the given values. The optional namespace parameter specifies the namespace mapping of prefix(es) in the XPath parameters.
updateXML() can be used to update, replace elements, attributes and other nodes with new values. They cannot be directly used to insert new nodes or delete existing ones. The containing parent element should be updated with the new values instead.
Text description of the illustration updatexmla.gif
updateXML() updates only the transient XML instance in memory. Use an SQL UPDATE statement to update data stored in tables. The updateXML() syntax is:
UPDATEXML(xmlinstance, xpath1, value_expr1 [, xpath2, value_expr2]...[,namespace_string]);
This example updates the XMLType using the UPDATE statement. It updates only those documents whose purchase order number is 2001.
UPDATE po_xml_tab e SET e.poDoc = XMLType( '<?xml version="1.0"?> <PO pono="2"> <PNAME>Po_2</PNAME> <CUSTNAME>Nance</CUSTNAME> <SHIPADDR> <STREET>2 Avocet Drive</STREET> <CITY>Redwood Shores</CITY> <STATE>CA</STATE> </SHIPADDR> </PO>') WHERE e.poDoc.EXTRACT('/PO/PONO/text()').getNumberVal() = 2001;
To update the XML document in the table instead of creating a new one, you can use the updateXML() in the right hand side of an UPDATE statement to update the document.
UPDATE po_xml_tab SET poDoc = UPDATEXML(poDoc, '/PO/CUSTNAME/text()', 'John'); 1 row updated SELECT e.poDoc.getstringval() AS newpo FROM po_xml_tab e; NEWPO -------------------------------------------------------------------- <?xml version="1.0"?> <PO pono="2"> <PNAME>Po_2</PNAME> <CUSTNAME>John</CUSTNAME> <SHIPADDR> <STREET>2 Avocet Drive</STREET> <CITY>Redwood Shores</CITY> <STATE>CA</STATE> </SHIPADDR> </PO>
You can update multiple elements within a single updateXML() expression. For instance, you can use the same UPDATE statement as shown in the preceding example and update purchase order, po:
UPDATE emp_tab e SET e.emp_col = UPDATEXML(e.emp_col, '/EMPLOYEES/EMP[EMPNAME="Joe"]/SALARY/text()',100000, '//EMP[EMPNAME="Jack"]/EMPNAME/text()','Jackson', '//EMP[EMPNO=217]',XMLTYPE.CREATEXML( '<EMP><EMPNO>217</EMPNO><EMPNAME>Jane</EMPNAME></EMP>')) WHERE EXISTSNODE(e.emp_col, '//EMP') = 1;
This updates all rows that have an employee element with the new values.
The following example updates the customer name in the purchase order XML document, po:
|
Note: This example only selects the document and the update occurs on a transient |
SELECT UPDATEXML(poDoc, '/PO/CUSTNAME/text()', 'John').getstringval() AS updatedPO FROM po_xml_tab; UPDATEDPO -------------------------------------------------------------------- <?xml version="1.0"?> <PO pono="2"> <PNAME>Po_2</PNAME> <CUSTNAME>John</CUSTNAME> <SHIPADDR> <STREET>2 Avocet Drive</STREET> <CITY>Redwood Shores</CITY> <STATE>CA</STATE> </SHIPADDR> </PO>
You can also use updateXML() to update multiple pieces of a transient instance. For example, consider the following XML document stored in column emp_col of table, emp_tab:
<EMPLOYEES> <EMP> <EMPNO>112</EMPNO> <EMPNAME>Joe</EMPNAME> <SALARY>50000</SALARY> </EMP> <EMP> <EMPNO>217</EMPNO> <EMPNAME>Jane</EMPNAME> <SALARY>60000</SALARY> </EMP> <EMP> <EMPNO>412</EMPNO> <EMPNAME>Jack</EMPNAME> <SALARY>40000</SALARY> </EMP> </EMPLOYEES>
To generate a new document with Joe's salary updated to 100,000, update the Name of Jack to Jackson, and modify the Employee element for 217, to remove the salary element. You can write a query such as:
SELECT UPDATEXML(emp_col, '/EMPLOYEES/EMP[EMPNAME="Joe"]/SALARY/text()', 100000, '//EMP[EMPNAME="Jack"]/EMPNAME/text()','Jackson', '//EMP[EMPNO=217]', XMLTYPE.CREATEXML('<EMP><EMPNO>217</EMPNO><EMPNAME>Jane</EMPNAME>')) FROM emp_tab e;
This generates the following updated XML:
<EMPLOYEES> <EMP> <EMPNO>112</EMPNO> <EMPNAME>Joe</EMPNAME> <SALARY>100000</SALARY> </EMP> <EMP> <EMPNO>217</EMPNO> <EMPNAME>Jane</EMPNAME> </EMP> <EMP> <EMPNO>412</EMPNO> <EMPNAME>Jackson</EMPNAME> <SALARY>40000</SALARY> </EMP> </EMPLOYEES>
You can use updateXML() to create new views of XML data. This can be useful when you do not want a particular set of users to see sensitive data such as SALARY.
A view such as:
CREATE VIEW new_emp_view AS SELECT UPDATEXML(emp_col, '/EMPLOYEES/EMP/SALARY/text()', 0) emp_view_col FROM emp_tab e;
ensures that users selecting from view, new_emp_view, do not see the SALARY field for any employee.
In most cases, updateXML() materializes the whole input XML document in memory and updates the values. However, it is optimized for UPDATE statements on XML schema-based object-relationally stored XMLType tables and columns so that the function updates the value directly in the column.
The conditions for rewrite are explained in Chapter 5, "Structured Mapping of XMLType", "Query Rewrite with XML Schema-Based Structured Storage", in detail. If all of the rewrite conditions are met, then the updateXML() is rewritten to update the object-relational columns directly with the values. For example, the following UPDATE statement:
UPDATE po_xml_tab SET poDoc = UPDATEXML(poDoc, '/PO/CUSTNAME/text()', 'John');
could get rewritten (if the rewrite rules are satisfied) to an UPDATE of the custname column directly:
UPDATE po_xml_tab p SET p.xmldata.CUSTNAME = 'John';
If you update an XML element to null, Oracle removes the attributes and children of the element, and the element becomes empty. The type and namespace properties of the element are retained. A NULL value for an element update is equivalent to setting the element to empty.
If you update the text node of an element to null, Oracle removes the text value of the element, and the element itself remains but is empty. For example, if you update node, '/empno/text()' with a NULL value, the text values for the empno element are removed and the empno element becomes empty.
Setting an attribute to NULL, similarly sets the value of the attribute to the empty string.
You cannot use updateXML() to remove, add, or delete a particular element or an attribute. You have to update the containing element with a new value.
|
Note: Setting ' |
Consider the XML document:
<PO> <pono>21</pono> <shipAddr gate="xxx"> <street>333</street> <city>333</city> </shipAddr> </PO>
The clause:
updateXML(xmlcol,'/PO/shipAddr',null)
is equivalent to making it:
<PO> <pono>21</pono> <shipAddr/> </PO>
If you update the text node to NULL, then this is equivalent to removing the text value alone. For example:
UPDATEXML(xmlcol,'/PO/shipAddr/street/text()', null)
results in:
<PO> <pono>21</pono> <shipAddr> <street/> <city>333</city> </shipAddr> </PO>
You can update the same XML node more than once in the updateXML() statement. For example, you can update both /EMP[EMPNO=217] and /EMP[EMPNAME="Jane"]/EMPNO, where the first XPath identifies the EMPNO node containing it as well. The order of updates is determined by the order of the XPath expressions in left-to-right order. Each successive XPath works on the result of the previous XPath update.
The XMLTransform() function takes in an XMLType instance and an XSLT stylesheet. It applies the stylesheet to the XML document and returns a transformed XML instance. See Figure 4-5.

XMLTransform() is explained in detail in Chapter 6, "Transforming and Validating XMLType Data".
DELETEs on the row containing the XMLType column are handled in the same way as any other datatype.
For example, to delete all purchase order rows with a purchase order name of "Po_2", execute a statement such as:
DELETE FROM po_xml_tab e WHERE e.poDoc.extract('/PO/PNAME/text()').getStringVal()='Po_2';
You can use the new and old binds inside triggers to read and modify the XMLType column values. For INSERT and UPDATE statements, you can modify the new value to change the value being inserted.
For example, you can write a trigger to change the purchase order if it does not contain a shipping address:
CREATE OR REPLACE TRIGGER po_trigger BEFORE INSERT OR UPDATE ON po_xml_tab FOR EACH ROW declare pono Number; begin
if inserting then:
if :NEW.poDoc.existsnode('//SHIPADDR') = 0 then :NEW.poDoc := xmltype('<PO>INVALID_PO</PO>'); end if; end if;
when updating, if the old poDoc has purchase order number different from the new one then make it an invalid PO.
if updating then:
if :OLD.poDoc.extract('//PONO/text()').getNumberVal() != :NEW.poDoc.extract('//PONO/text()').getNumberVal() then :NEW.poDoc := xmltype('<PO>INVALID_PO</PO>'); end if; end if; end; /
This example is only an illustration. You can use the XMLType value to perform useful operations inside the trigger, such as validation of business logic or rules that the XML document should conform to, auditing, and so on.
You can create the following indexes when using XMLType. Indexing speeds up query evaluation.
You can speed up by queries by building function-based indexes on existsNode() or those portions of the XML document that use extract().
For example, to speed up the search on the query,
SELECT * FROM po_xml_tab e WHERE e.poDoc.extract('//PONO/text()').getNumberVal()= 100;
you can create a function-based index on the extract() function as follows:
CREATE INDEX city_index ON po_xml_tab (poDoc.extract('//PONO/text()').getNumberVal());
The SQL query uses this function-based index, to evaluate the predicate instead of parsing the XML document row by row, and evaluating the XPath expression.
You can also create bitmapped function-based indexes to speed up the evaluation of the operators. existsNode() is suitable, since it returns a value of 1 or 0 depending on whether the XPath is satisfied in the XML document or not.
For example, to speed up a query that searches whether the XML document contains an element called Shipping address (SHIPADDR) at any level:
SELECT * FROM po_xml_tab e WHERE e.poDoc.existsNode('//SHIPADDR') = 1;
you can create a bitmapped function-based index on the existsNode() function as follows:
CREATE BITMAP INDEX po_index ON po_xml_tab (poDoc.existsNode('//SHIPADDR'));
This speeds up the query processing.
Oracle Text index works on CLOB and VARCHAR columns. It has been extended in Oracle9i to also work on XMLType columns. The default behavior of Oracle Text index is to automatically create XML sections, when defined over XMLType columns. Oracle Text also provides the CONTAINS operator which has been extended to support XPath.
In general, Oracle Text indexes can be created using the CREATE INDEX SQL statement with the INDEXTYPE specified as for other CLOB or VARCHAR columns. Oracle Text indexes on XMLType columns, however, are created as function-based indexes.
CREATE INDEX po_text_index ON po_xml_tab(poDoc) indextype is ctxsys.context;
You can also perform Oracle Text operations such as CONTAINS and SCORE. on XMLType columns. In Oracle9i Release (9.0.1), the CONTAINS operator was enhanced to support XPath using two new operators, INPATH and HASPATH:
For example:
SELECT * FROM po_xml_tab w WHERE CONTAINS(w.poDoc, 'haspath(/PO[./@CUSTNAME="John Nike"])') > 0;
In Oracle9i Release (9.0.1), to create and use Oracle Text index in queries, in addition to having the privileges for creating indexes and for creating Oracle Text indexes, you also needed privileges and settings for creating function-based indexes:
QUERY_REWRITE privilege. You must have this privilege granted to create text indexes on XMLType columns in your own schema.GLOBAL_QUERY_REWRITE privilege. If you need to create Oracle Text indexes on XMLType columns in other schemas or on tables residing in other schemas, you must have this privilege granted.Oracle Text index uses the PATH_SECTION_GROUP as the default section group when indexing XMLType columns. This default can be overridden during Oracle Text index creation.
With this release, you no longer need the additional QUERY_REWRITE privileges when creating Oracle Text indexes.
|
Note: The |
existsNode() SQL function, unlike the CONTAINS operator, cannot use Oracle Text indexes to speed up its evaluation. To improve the performance of XPath searches in existsNode(), this release introduces a new index type, CTXXPATH.
CTXXPATH index is a new indextype provided by Oracle Text. It is designed to serve as a primary filter for existsNode() processing, that is, it produces a superset of the results that would be produced by the existNode() function. The existsNode() functional implementation is then applied on the results to return the correct set of rows.
CTXXPATH index can handle XPath path searching, wildcards, and string equality predicates.
CREATE INDEX po_text_index ON po_xml_tab(poDoc) indextype is ctxsys.ctxxpath;
For example, a query such as:
SELECT * FROM po_xml_doc w WHERE existsNode(w.poDoc,'/PO[@CUSTNAME="John Nike"]') = 1;
could potentially use CTXXPATH indexing to satisfy the existsNode() predicate.
The differences in XPath support when using CONTAINS compared to XPath support with existsNode() and extract() functions are:
<A> <B> <C> </C> </B> <D> <E> </E> </D> </A>
the XPath expression - A/B/E falsely matches the preceding XML document.
existsNode() or extract() operations on the remainder of the XML documents.
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|

